
Hermes Kanban:4 个 Agent 怎么像团队一样干活


AI Agent 本该像团队一样协作。
你描述目标,它们分工干活,一个接一个往下传递——这是理想状态。
现实恰恰相反。每个 Agent 从零开始,不知道其他 Agent 做了什么、改了哪些文件、接口长什么样。每次交接都是冷启动,任务质量在跨 Agent 传递的时候就开始打折扣。
Hermes Kanban 解决了这个问题。
每个任务都能在崩溃和重启中存活。每份任务简报精确携带下一个 Agent 所需的一切信息。每次失败都被完整记录,重试的时候能准确知道哪里出了问题。
最棒的是——整个团队可以从手机上操控。你在 Telegram 上创建和推进任务,Agent 在你离开电脑时自动接手干活。
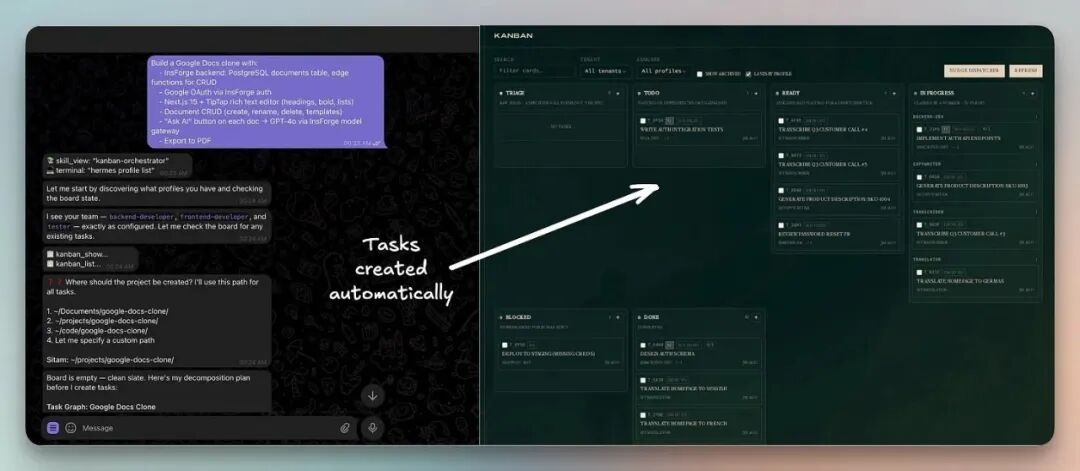
本文从零搭建完整系统:协调模型、任务简报机制、一个 4 人 Agent 软件团队,大约 20 分钟搞定。
为了演示效果,我用这个 Agent 团队搭建了一个可运行的 Google Docs 克隆版,包含 AI 功能、生产级后端,全部由这个 Agent 团队自主完成。
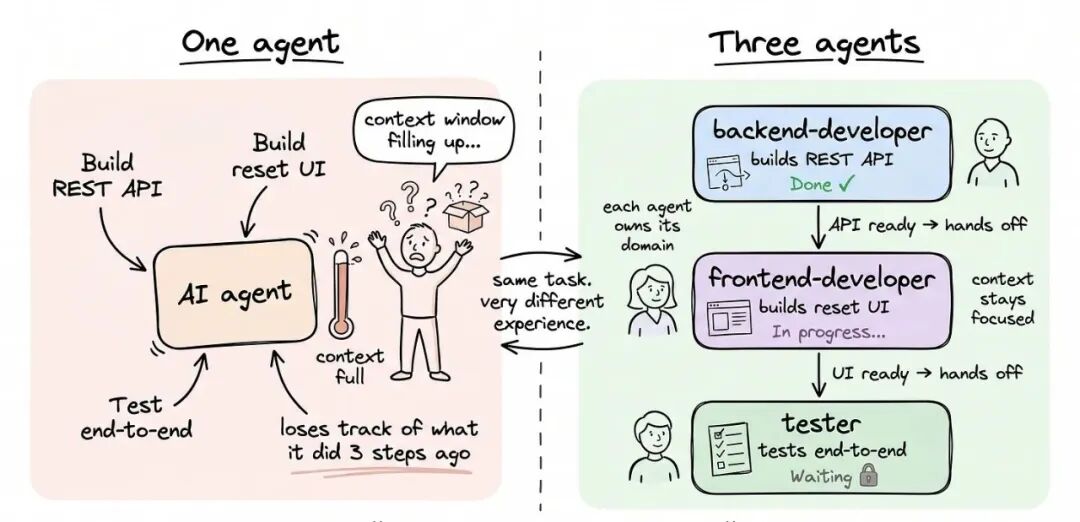
为什么一个 Agent 不够
比如你想加个密码重置功能,工作自然分成三块:后端写接口、前端对接接口做界面、测试端到端验证。
你可以让一个 Agent 全干,但上下文窗口很快就满了——三步之前做了什么它已经忘了。你花在管理它的时间,比它帮你省的还多。
把工作拆给各自领域的 Agent 又会产生新问题:前端 Agent 怎么知道后端做了什么?接口叫什么?字段是什么?
这就是 Hermes Kanban 要解决的共享上下文问题。
核心模型
传统的看板很简单:任务有标题、描述、负责人和状态,有人领走、推进、关闭。看板是唯一的依据。
Hermes Kanban 保留了这套模型,只是把人换成了 Agent。
每个任务看板卡片在崩溃和重启中都能存活。Agent 完成工作时会写一份摘要:改了哪些文件、做了什么、下一个 Agent 需要知道什么。
下一个 Agent 开工之前,先读这份摘要。
这个摘要才是整个系统的核心——它把一群互不相识的 Agent 变成了一支真正的团队。

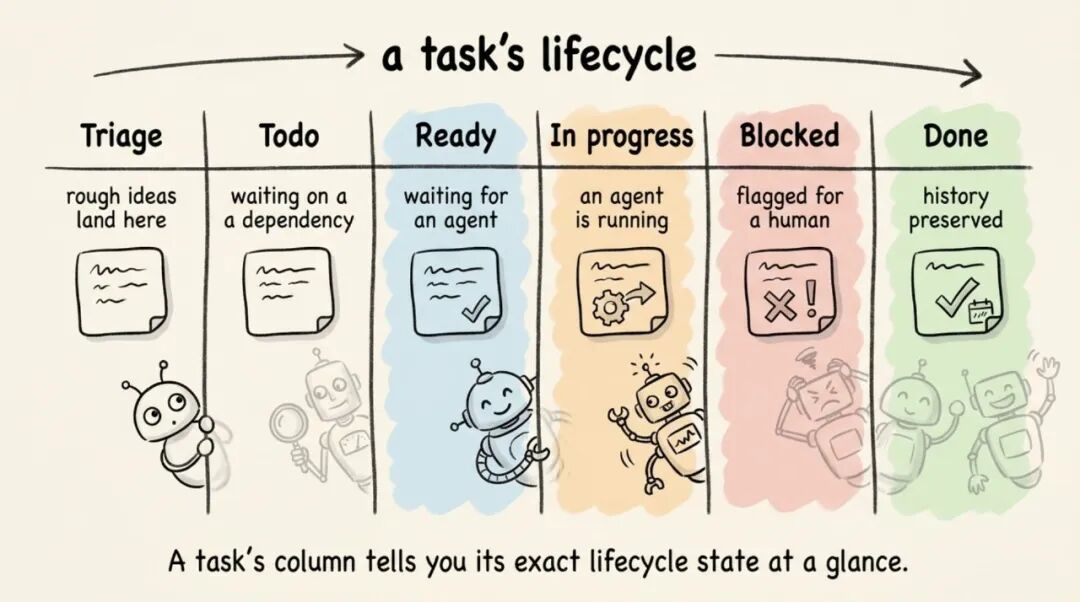
看板六列
一张看板,六个状态列:
- 分流(Triage):粗略想法先落这里。比如”我想要登录鉴权”这种还没完整需求规格的,先丢进来
- 待办(Todo):任务已创建,但等前置依赖完成
- 就绪(Ready):依赖满足了,等 Agent 来领
- 进行中(In Progress):Agent 正在跑
- 阻塞(Blocked):Agent 撞墙了,标记给人来处理
- 完成(Done):含完整运行历史、摘要和元数据
编排者
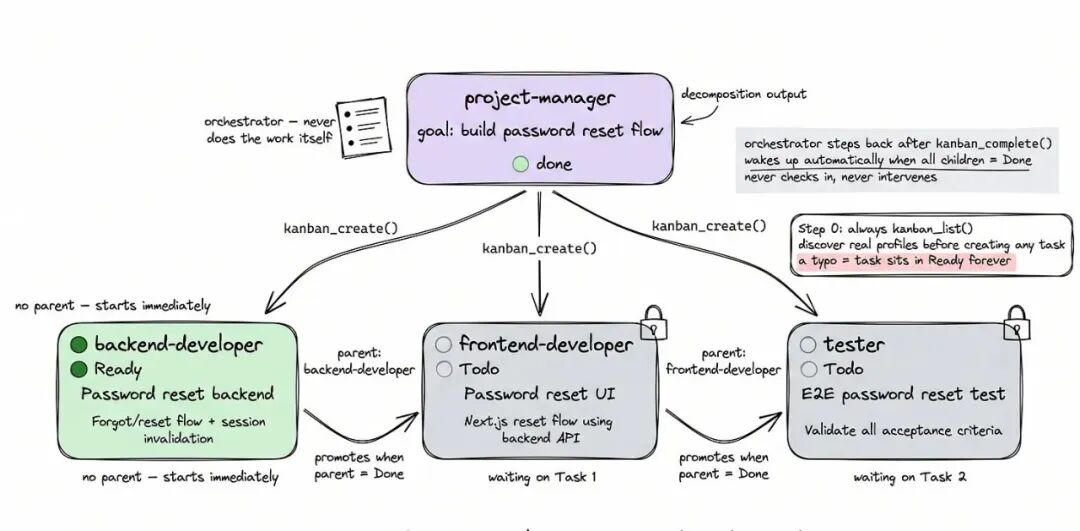
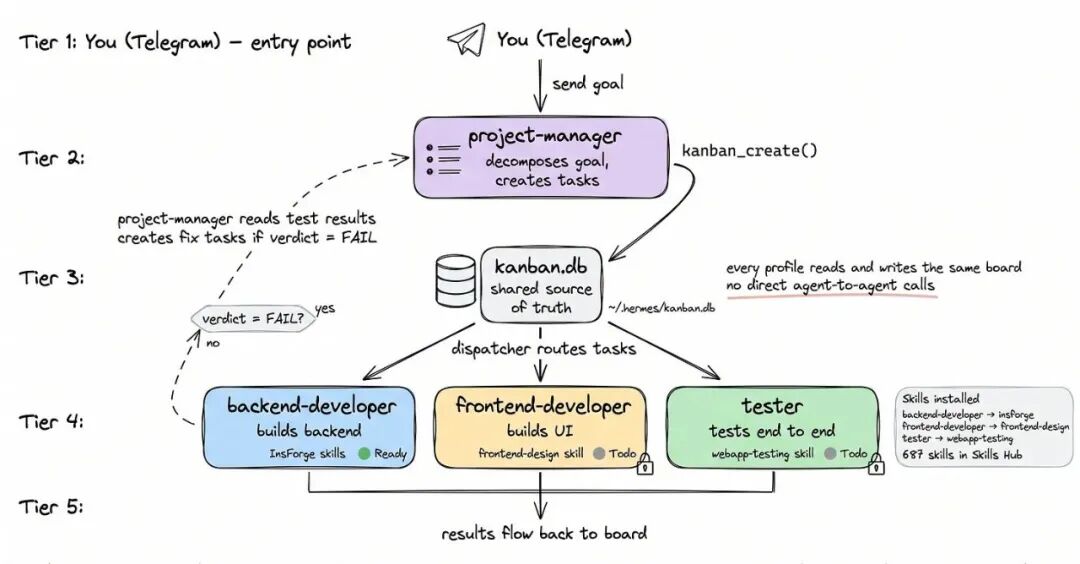
编排 Agent(Orchestrator)就是整个团队的项目经理。
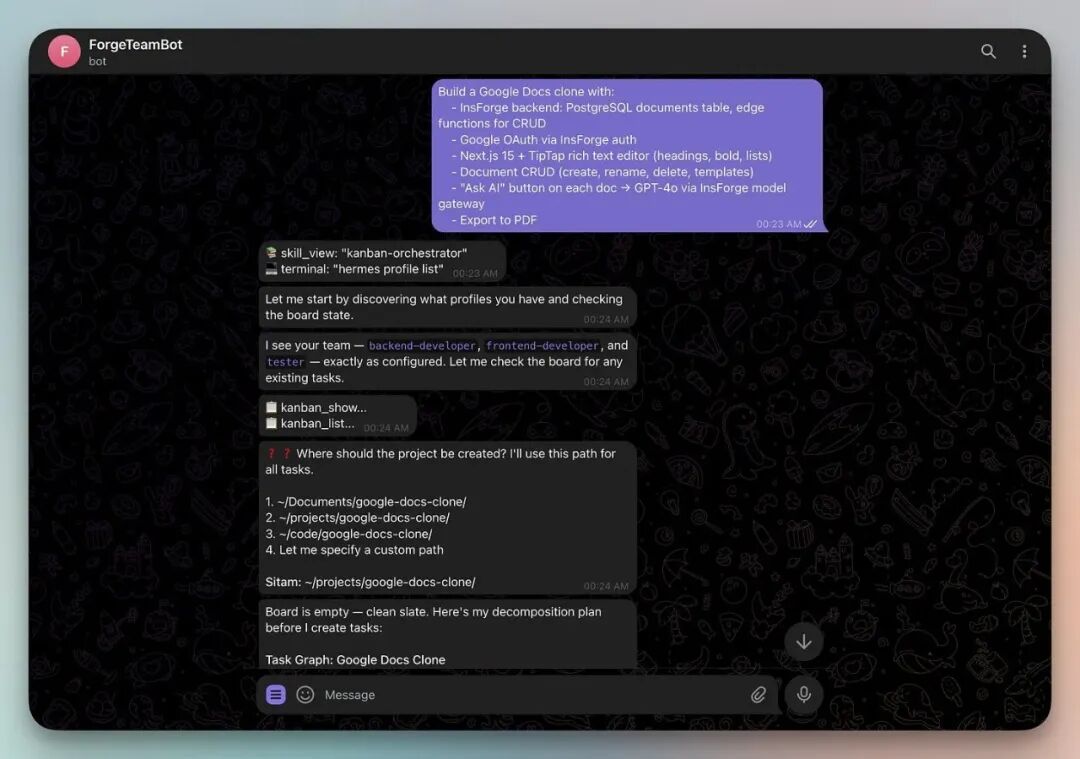
它读你的高层目标,查有哪些 Agent 可用,把目标拆成相互关联的任务卡片,然后退后——它自己不写代码、不跑测试,只做协调。
有一条关键规则:创建任务之前,先查一下现有的 Agent 配置(profile)列表。系统会静默跳过那些没有匹配到真实 Agent 的任务,所以第一步永远是先看清团队里有什么人。
但实际上,你什么都不用操心。在 Telegram 上给项目经理说一句需求,编排者自动接手,拆任务、分配、推进,全程自动走完。
三种协作模式
流水线模式(Pipeline):任务依次依赖,A 做完 B 才能开始,B 做完 C 才能开始。只有第一个任务从”就绪”状态开始,其余排队等前置完成。
人工介入模式(Human in the Loop):Agent 做到一半发现拿不准的地方,主动停下来问人。你在手机上看板里验证、修复、解除阻塞,然后它继续跑。
分流补全模式(Triage Specifier):粗略想法随手丢进”分流”列,系统自动把它展开成一份有完整需求规格的任务卡片。
搭建步骤
四个 Agent、一块共享看板、项目经理通过 Telegram 可达。具体步骤:
- 创建 Agent 配置:用hermes profile create –clone给每个角色建独立配置
- 写 SOUL.md:给每个 Agent 定义身份和思维方式(项目经理、后端开发、前端开发、测试各一个)
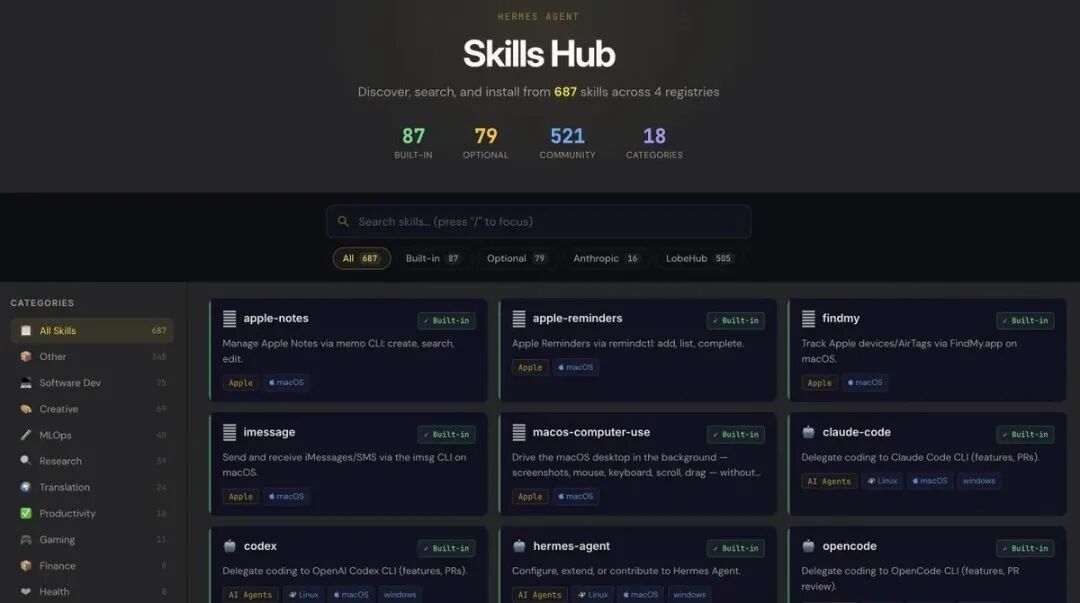
- 装技能包:从 687 个可选技能包里挑合适的(后端有 InsForge、前端有 frontend-design、测试有 webapp-testing 等)
- 初始化看板:hermes kanban init,创建本地数据库
- 启动网关:用 Telegram 的 @BotFather 拿 bot 令牌,@userinfobot 拿你的用户 ID
- 发第一个项目:在 Telegram 上跟项目经理说需求,它自动拆任务分配
演示项目:Google Docs 克隆版
为了验证整个流程能跑通,我用这个 4 人 Agent 团队从零搭建了一个 Google Docs 克隆版——包含 AI 功能、生产级后端,全部由 Agent 自主完成。
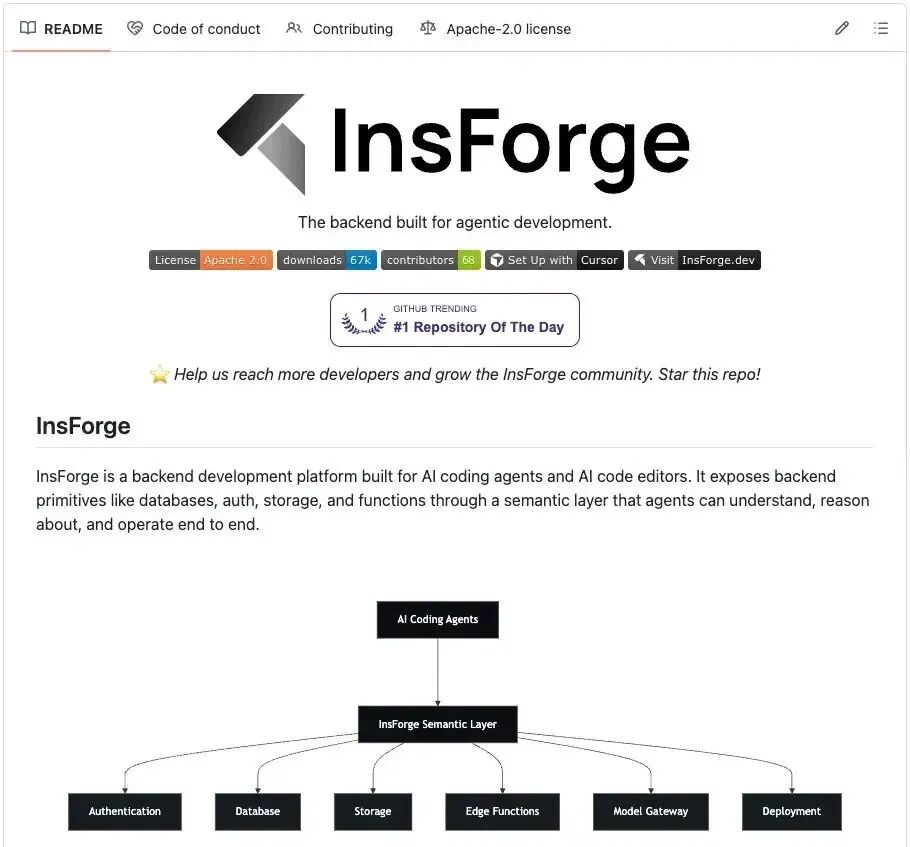
后端基于 InsForge(开源),Agent 自动生成了数据库模型、REST 接口和完整的后台管理面板。
技能包从 687 个中按需挑选,后端、前端、测试各有对应的专用包。
踩坑提醒
数据库过载:2-4 个 Agent 并行没问题,10 个以上同时高频写入会变慢。用hermes kanban dispatch –max 4限制并发数。
临时工作空间会被清:任务完成时,Agent 的临时工作目录(scratch)会被擦除。编码任务建议用 git worktree,或者在任务描述里写明项目的固定路径。
本地模型扛不住:多个 Agent 同时跑本地 GPU 容易压垮,用–max 2限制并行数。如果用云端 API(Claude、GPT-4o 这些),基本不用担心。
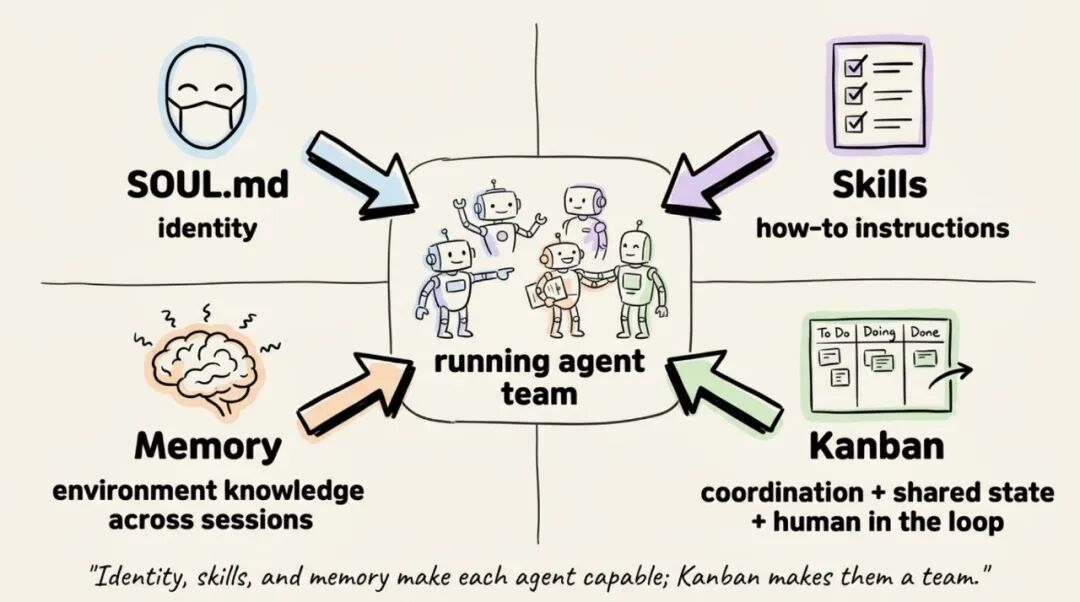
全貌一张图
- SOUL.md= Agent 的固定身份(它是谁、怎么思考)
- 技能包(Skills)= 具体工作的步骤指南
- 记忆(Memory)= 跨会话沉淀的环境知识
- 看板(Kanban)= 协调层:共享状态、上下文传递、随时可人工介入
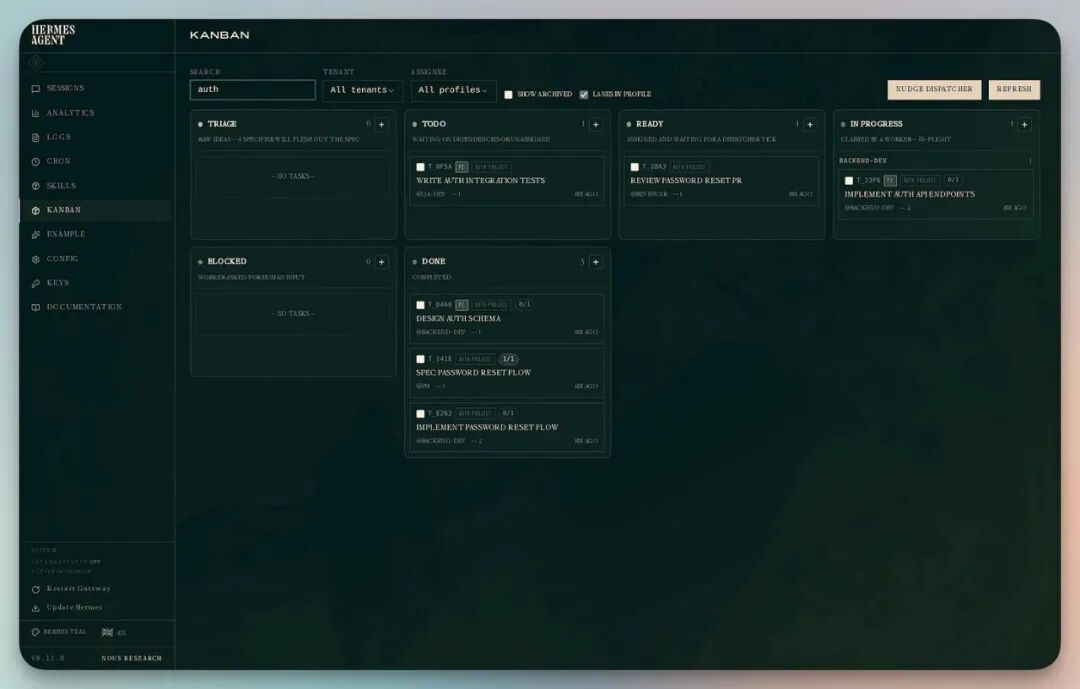
看板实际长什么样
每列对应一个状态,每张卡片对应一个任务。Agent 完成工作后自动移动卡片。
可以按 Agent 分列查看——谁在干什么一目了然。
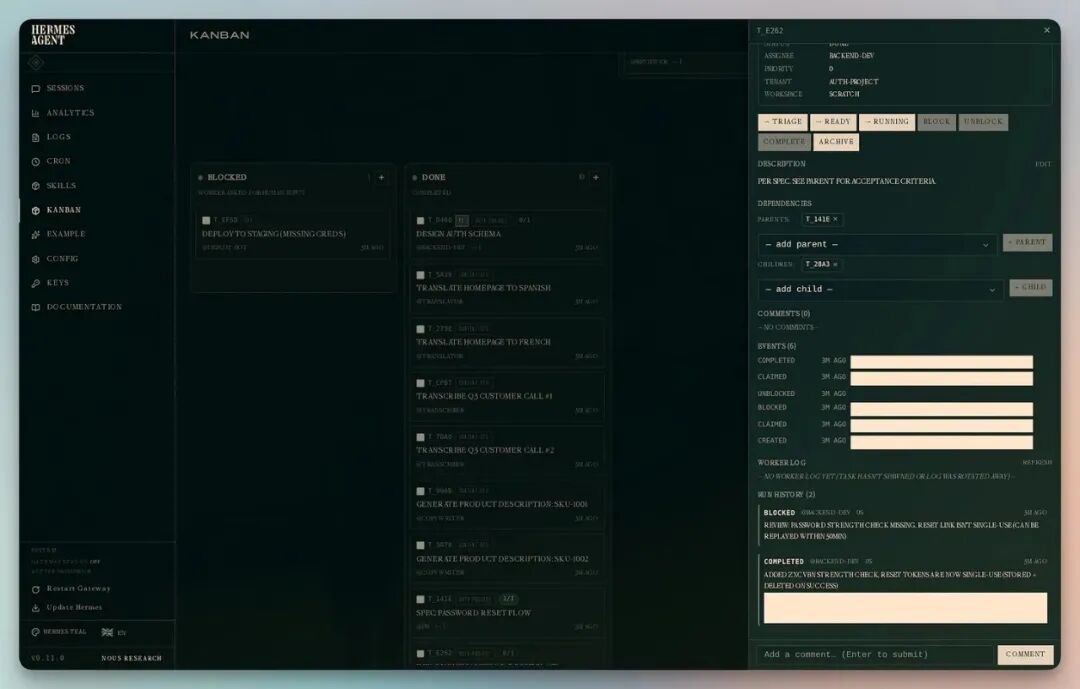
点开卡片能看到完整信息:任务描述、运行日志、摘要、进程 ID、完成标准。
评论区观点
文章发出去之后,评论区最有意思的讨论集中在两个方向:交互方式和数据架构。
交互层面,最大的痛点是浏览器里套终端——想解除一个阻塞,还得切到命令行去操作,体验确实拉胯。有人很快给出了方案:一个开源的聊天优先的 Hermes Web UI,自己部署直接对接现有的环境。Akshay 本人也回应说这正好补上了文章里提到的最大短板。从这些反馈能看出来,看板的协调模型本身没太大争议,真正的瓶颈在交互层——怎么让人更方便地介入和操控。
数据架构层面,有人分享了用知识图谱混合数据库替代纯看板的做法,额外加了影响范围检查、文件依赖追踪、不变量目录等防护机制。这个方向挺有前瞻性的,因为看板本质上是个轻量的状态机,当 Agent 团队规模变大、任务关联变复杂之后,纯看板可能不够用,需要更结构化的知识表示。还有一个很实际的问题:Agent 写的摘要太长会被截断,关键信息就丢了。
另外也有人提到/goal命令是解锁看板全部能力的关键——标准化的任务指令格式加可视化的协调层,两个加在一起才完整。
下一篇我们聊/goal——这个让 Codex、Claude Code 和 Hermes 三个工具说同一种语言的底层标准。
作者:jovi_AI电报
扫一扫 微信咨询

商务合作 联系我们
 微信扫一扫
微信扫一扫 



