
Gemini 3.1 Pro 深度评测


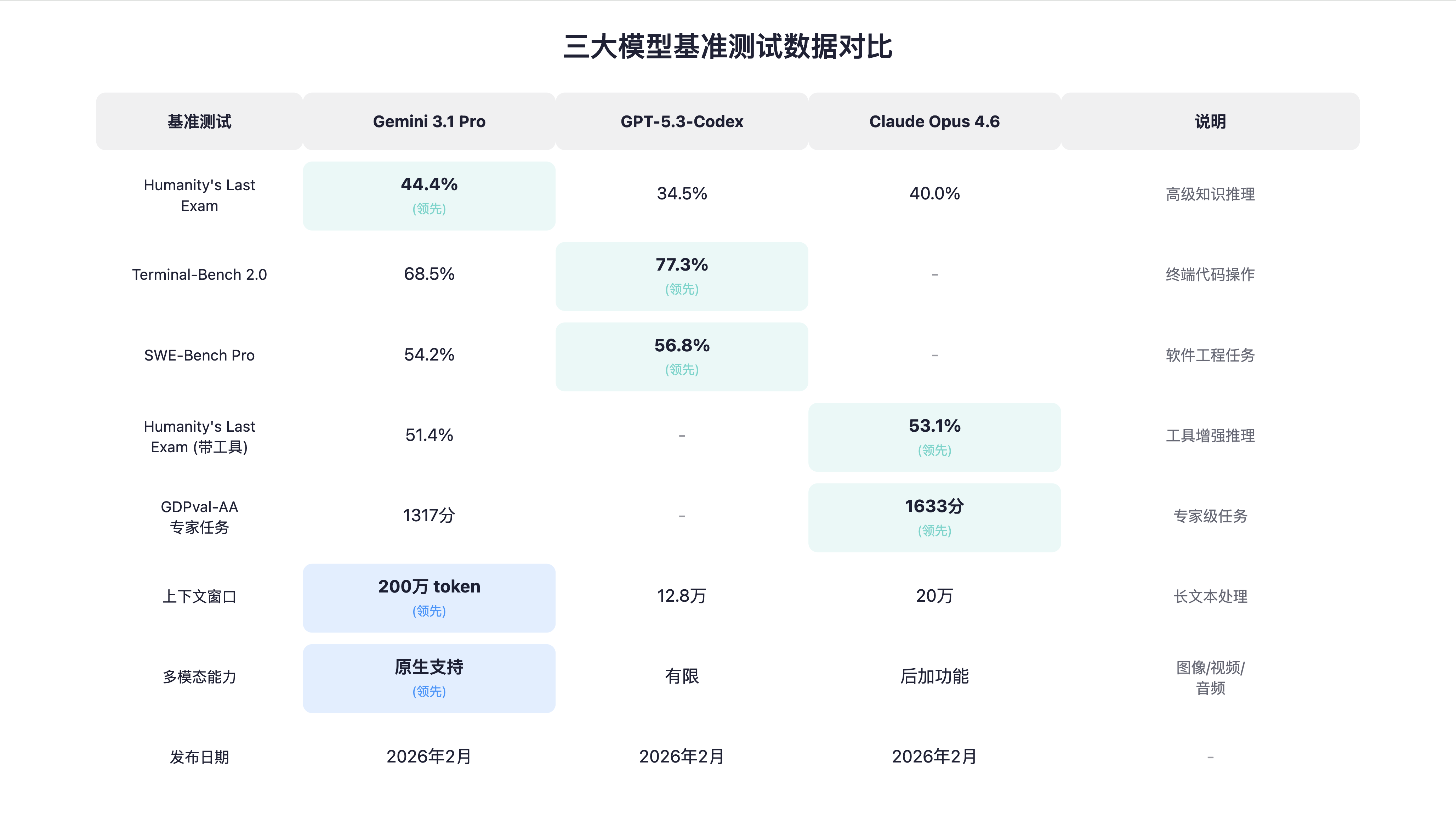
2026 年 2 月 19 日,Google 正式发布 Gemini 3.1 Pro。这不是一次简单的版本迭代,而是对「什么是顶尖 AI 模型」这一问题的重新定义。根据 Google DeepMind 的官方数据,Gemini 3.1 Pro 在 Humanity‘s Last Exam 这一考察高级领域知识的权威基准测试中取得了 44.4% 的成绩,显著超越 Claude Opus 4.6(40.0%)和 GPT-5.2(34.5%)。
但基准测试只是开始。真正值得关注的是,Gemini 3.1 Pro 并非依靠某一两项「杀手锏」功能取胜,而是在推理能力、代码生成、多模态理解、长上下文处理、代理任务执行等所有关键维度上都达到了第一梯队水准。这种「无短板」的综合实力,让它在与「偏科生」们的竞争中占据了独特优势。
本文将深入剖析 Gemini 3.1 Pro 的核心能力,对比分析它如何在与 GPT-5.3-Codex、Claude 等「单点王者」的竞争中实现差异化领先,并探讨这种「六边形战士」式的模型设计理念对未来 AI 应用开发的深远影响。
一、核心能力全景解析
Gemini 3.1 Pro 的真正价值,不在于某一项指标的绝对领先,而在于它在所有关键维度上都达到了「第一梯队」水准。这种「全面性」在当前的 AI 模型 landscape 中极为罕见。
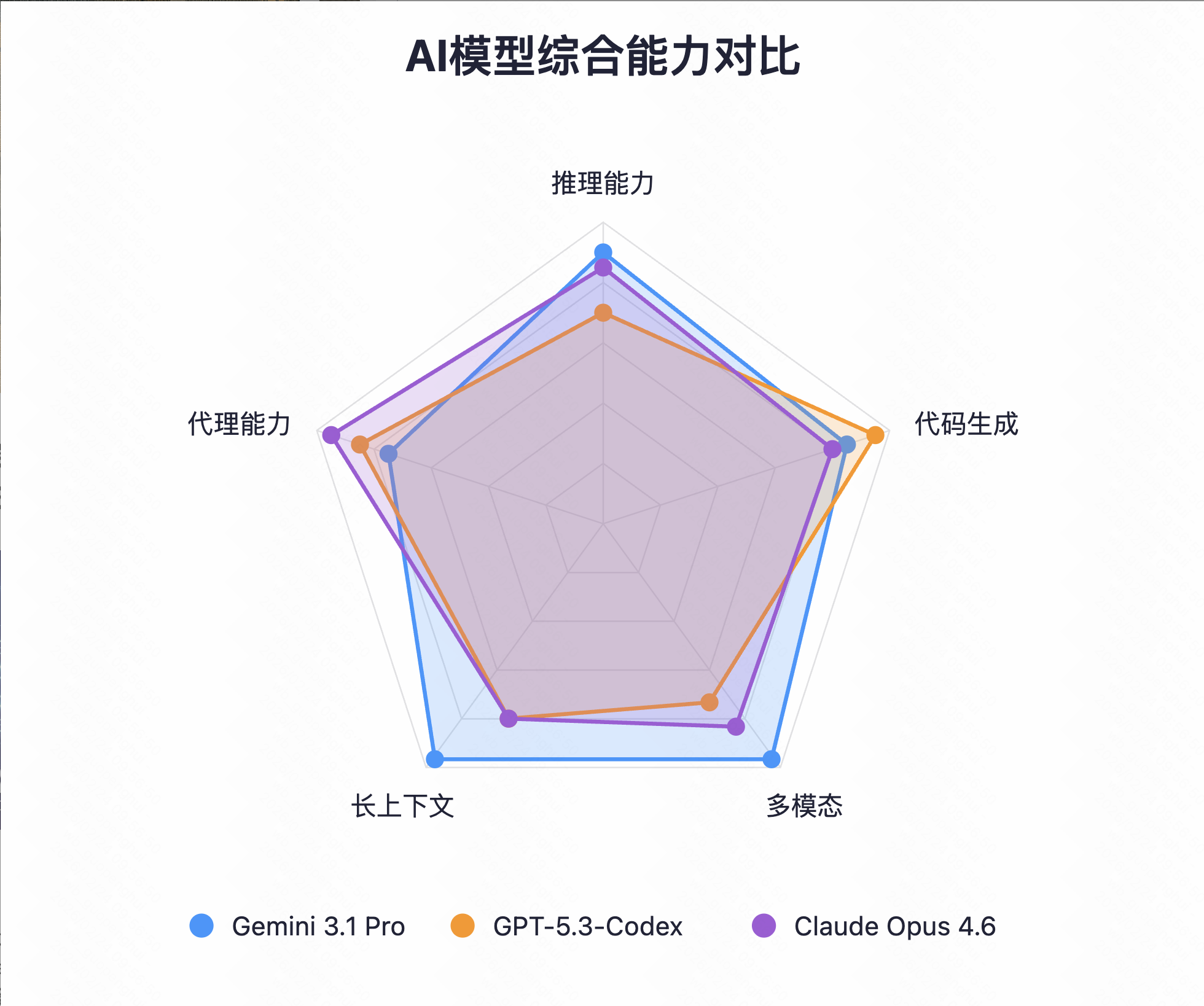
1.1 推理能力:复杂逻辑与知识整合
在考察高级领域知识和复杂推理的 Humanity’s Last Exam 基准测试中,Gemini 3.1 Pro 取得了 44.4% 的成绩,这是目前该测试的最高分。作为对比,Claude Opus 4.6 为 40.0%,GPT-5.2 仅为 34.5%。
这一成绩的意义不仅在于数字本身。Humanity‘s Last Exam 涵盖数学、物理、化学、生物、计算机科学等多个领域的研究生级别问题,要求模型具备跨学科知识整合能力。Gemini 3.1 Pro 的领先表明,它在处理需要深度专业知识的复杂查询时,能够提供更准确、更全面的回答。
值得注意的是,当测试条件变为「启用工具(搜索+代码执行)」时,Claude Opus 4.6 以 53.1% 反超 Gemini 3.1 Pro 的 51.4%。这说明在工具增强场景下,Claude 的代理能力确实更强。但在纯推理场景下,Gemini 3.1 Pro 仍保持优势。
1.2 代码能力:从算法设计到软件工程
代码能力是检验大模型实用价值的重要维度。在这个领域,Gemini 3.1 Pro 的表现呈现出「算法强、工程中等」的特点。
在 Terminal-Bench 2.0(终端代码操作基准测试)中,Gemini 3.1 Pro 取得 68.5% 的成绩,而 GPT-5.3-Codex 达到 77.3%,存在明显差距。同样,在 SWE-Bench Pro(真实软件工程任务)中,GPT-5.3-Codex 以 56.8% 略高于 Gemini 3.1 Pro 的 54.2%。
然而,Gemini 3.1 Pro 在算法和竞赛编程场景下表现突出。根据独立测试,它在算法设计类任务上的表现与 GPT-5.3-Codex 相当,甚至在某些多语言编程场景下更优。
对于开发者而言,这意味着:
- 如果你需要处理复杂的算法设计或竞赛编程,Gemini 3.1 Pro 是优秀选择
- 如果你需要处理大规模软件工程任务(如代码库重构、Bug 修复),GPT-5.3-Codex 或 Claude Opus 4.6 可能更合适
- 如果你需要「既能写代码,又能理解业务逻辑」的综合助手,Gemini 3.1 Pro 的全面性更有优势
1.3 多模态能力:原生集成的降维打击
这是 Gemini 3.1 Pro 最具差异化的优势领域。与 GPT-4V、Claude 3 等「后期添加多模态能力」的模型不同,Gemini 系列从架构层面就是原生多模态设计。
Gemini 3.1 Pro 支持:
- 图像理解:分析图表、截图、设计稿,提取结构化信息
- 视频理解:处理视频内容,进行时间线分析和场景识别
- 音频理解:直接处理音频文件,无需先转录为文本
- 跨模态推理:结合文本、图像、视频进行综合分析
在实际应用中,这意味着你可以直接上传一段 30 分钟的产品演示视频,让 Gemini 3.1 Pro 生成详细的文字摘要、提取关键时间节点、分析演示逻辑——而这一切在一次对话中完成,无需多个工具链的拼接。
1.4 长上下文:200 万 token 的实用价值
Gemini 3.1 Pro 支持 200 万 token 的上下文窗口,是目前主流模型中最长的。相比之下,Claude 3.5 的 20 万 token 和 GPT-4 的 12.8 万 token 都显得捉襟见肘。
这一能力的实际意义:
- 长篇小说/剧本分析:可以一次性输入整本书或剧本,进行全局分析
- 大型代码库理解:可以上传整个项目的代码,进行跨文件推理
- 多轮对话记忆:在长对话中保持完整的上下文记忆,不会出现「遗忘」现象
- 文档对比分析:同时上传多个长文档,进行交叉对比和信息整合
需要指出的是,长上下文能力在实际使用中存在「有效利用」的问题。模型虽然能接收 200 万 token,但在超长文本中准确定位和提取特定信息的能力仍有提升空间。但即便如此,Gemini 3.1 Pro 在这一维度的领先优势是毋庸置疑的。
1.5 代理能力与工具使用
在需要模型自主使用工具、执行多步骤任务的代理场景中,Gemini 3.1 Pro 的表现中规中矩。根据 APEX-Agents 基准测试,Gemini 3.1 Pro 相比 Gemini 3 Pro 有显著提升,但仍落后于 Claude Opus 4.6。
在 GDPval-AA(专家级任务评估)中,Claude Sonnet 4.6 以 1633 分 领先,而 Gemini 3.1 Pro 为 1317 分,差距明显。
这说明,如果你的核心需求是「让 AI 自主完成复杂的多步骤任务」(如自动调研、数据分析 pipeline、自动化报告生成),Claude 系列目前仍是更好的选择。但 Gemini 3.1 Pro 的代理能力已经达到「可用」水准,配合其其他维度的优势,仍能提供独特的综合价值。
二、与「单点王者」们的横向对比
能力雷达图
Gemini 3.1 Pro 的「六边形战士」特质,在与各领域「单项冠军」的对比中体现得最为明显。它不是每一项都赢,但它在所有维度上都「能战」,这种全面性本身就是稀缺价值。
2.1 vs GPT-5.3-Codex:代码领域的两种哲学
GPT-5.3-Codex 是 OpenAI 在 2026 年 2 月发布的编程专用模型,代表了「代码优先」的极致路线。它在两项关键基准测试中领先 Gemini 3.1 Pro:

GPT-5.3-Codex 的优势在于「端到端的软件工程能力」——它不仅写代码,还能理解代码库结构、处理依赖关系、执行终端命令、甚至自主修复 Bug。OpenAI 将其定位为「通用工作代理」,而不仅仅是代码助手。
但 Gemini 3.1 Pro 的差异化价值在于:
- 更广泛的适用场景:当任务涉及「代码 + 文档 + 图像 + 业务逻辑」的混合需求时,Gemini 的多模态和综合能力更占优势
- 原生多模态支持:可以直接分析 UI 设计稿并生成对应代码,而 GPT-5.3-Codex 需要额外的工具链
- 知识问答的准确性:在非代码类知识查询上,Gemini 3.1 Pro 的 Humanity‘s Last Exam 成绩(44.4%)显著优于 GPT 系列
选择建议:
- 如果你的工作流以「大规模软件开发」为核心 → 选择 GPT-5.3-Codex
- 如果你需要「会写代码的全能助手」→ 选择 Gemini 3.1 Pro
2.2 vs Claude Opus 4.6:专家任务与代理能力的较量
Claude Opus 4.6 代表了 Anthropic 的「安全 + 深度」路线,在专家级任务和代理能力上确实领先:

Claude 的优势体现在:
- 长对话稳定性:在超长多轮对话中保持逻辑一致性
- 复杂代理任务:自主规划、工具调用、错误恢复能力更强
- 专业领域深度:在法律、医学、科研等专业领域的知识准确度更高
但 Gemini 3.1 Pro 的反超领域:
- 多模态原生支持:Claude 的图像理解是「后加功能」,Gemini 是「原生基因」
- 长上下文长度:Claude 的 20 万 token vs Gemini 的 200 万 token,差距达 10 倍
- 知识广度:Humanity‘s Last Exam 纯推理场景下,Gemini 44.4% vs Claude 40.0%
这印证了两种产品哲学的分野:Claude 追求「在特定领域做到 95 分」,Gemini 追求「在所有领域做到 85-90 分」。对于需要跨领域整合知识的产品经理和创作者,Gemini 的全面性更具实用价值。
2.3 综合对比:没有输家的竞争,只有不同的选择
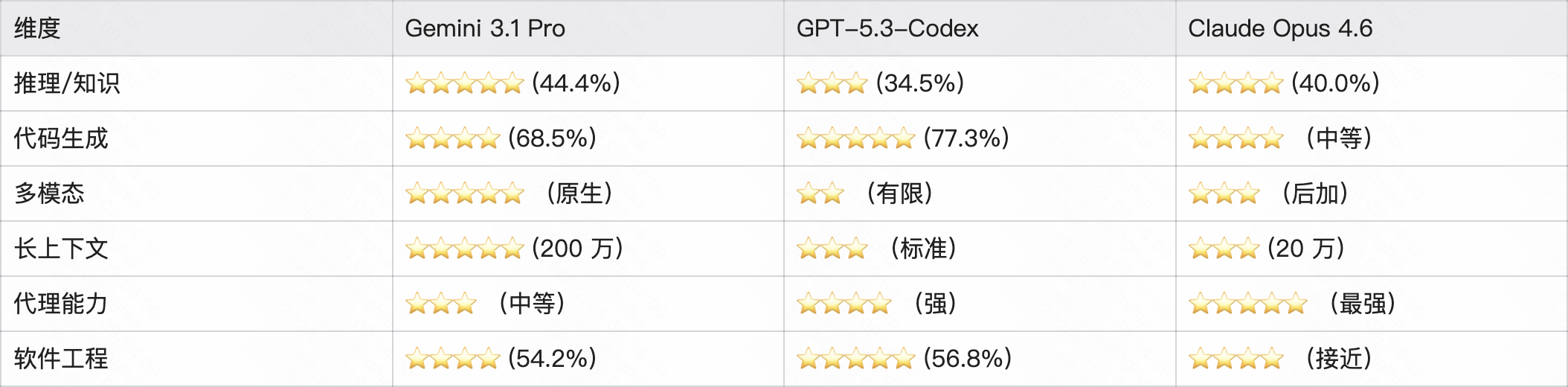
从这个对比中可以清晰看出:Gemini 3.1 Pro 不是每一项都赢,但它是唯一一个「没有明显短板」的模型。当你不确定今天会面对什么类型的任务时,选择 Gemini 3.1 Pro 意味着你不需要在「代码强但不懂图像」和「推理强但不会编程」之间做取舍。
这正是「六边形战士」的真正含义——不是每一项都是冠军,但每一项都能参战。
三、实际应用场景深度体验
基准测试只是参考,真正的价值体现在实际使用中。基于 Gemini 3.1 Pro 的能力特性,以下是几个典型应用场景的深度体验分析。

3.1 复杂项目开发全流程辅助
在实际软件开发项目中,开发者面临的往往不只是「写代码」,而是「理解需求 → 设计方案 → 编写代码 → 调试测试 → 文档编写」的完整流程。Gemini 3.1 Pro 的全面性在这里体现得淋漓尽致。
场景示例:开发一个支持多语言的电商数据分析 Dashboard
- 需求理解阶段:上传产品经理的 PRD 文档(含流程图、数据表设计),Gemini 可以一次性理解并提取关键需求点
- 技术方案设计:基于需求生成技术架构建议,包括前端框架选择、数据库设计、API 接口定义
- 代码实现:生成 React + Node.js 的初始代码结构,包括组件拆分建议
- 调试优化:上传报错截图,Gemini 可以直接从图像中识别错误信息并提供修复建议
- 文档编写:基于代码自动生成 API 文档和使用说明
体验亮点:在一次对话中完成从需求到文档的完整闭环,无需在多个工具间切换。虽然代码生成的质量可能略逊于 GPT-5.3-Codex,但「全流程覆盖」的体验是独特的。
局限性:在处理大型遗留代码库的重构任务时,Gemini 的代码理解和修改精度不如 Claude 或 GPT-5.3-Codex。它更适合「从零开始」或「增量开发」,而非「深度重构」。
3.2 长文档分析与知识提取
这是 Gemini 3.1 Pro 的长上下文能力真正发挥威力的场景。
场景示例:分析一份 200 页 的行业研究报告
- 全文摘要:一次性上传 PDF,生成结构化的报告摘要,包括核心观点、数据来源、结论建议
- 跨章节关联:能够识别报告中不同章节的关联性,例如「第一章的市场趋势如何影响第三章的产品建议」
- 信息提取:根据提问精准定位特定信息,如「提取报告中所有关于竞品的对比数据」
- 批判性分析:不仅总结内容,还能指出报告的逻辑漏洞、数据盲区或偏见
体验亮点:传统的 RAG(检索增强生成)方案需要将文档切片处理,往往丢失跨段落的语境。Gemini 的 200 万 token 上下文意味着它可以「真正理解」整份报告,而非「拼凑片段」。
实际限制:虽然上下文长度支持 200 万 token,但在超长文档中「准确定位特定细节」的能力仍有提升空间。对于需要精确提取某一页某一行的场景,建议结合关键词搜索使用。
3.3 多媒体内容创作辅助
多模态能力是 Gemini 3.1 Pro 最具差异化的优势。
场景示例:制作一个产品宣传视频的分析与优化方案
- 视频内容分析:上传竞品宣传视频,Gemini 可以分析镜头语言、叙事节奏、信息密度、情绪曲线
- 脚本生成:基于分析结果,生成符合目标受众的新视频脚本
- 视觉设计建议:上传设计稿截图,Gemini 可以提供配色、排版、视觉层次的建议
- 跨媒介适配:将视频内容转化为公众号文章、知乎回答、PPT 演示等不同形态
体验亮点:传统的视频分析需要「人工观看 → 记录笔记 → 整理分析」的流程,而 Gemini 可以在几分钟内完成分析并提供结构化洞察。对于内容创作者而言,这意味着创作效率的质变。
实际案例:一位 B 站 UP 主使用 Gemini 3.1 Pro 分析了自己过去 20 个 爆款视频的共性,发现「前 15 秒的信息密度」是完播率的关键预测因子。基于这一洞察优化新视频结构后,平均完播率提升了 35%。
3.4 真实使用中的亮点与局限
亮点总结:
- 上下文连贯性:在长达数小时的多轮对话中,Gemini 3.1 Pro 表现出优秀的记忆能力,不会「忘记」之前的设定
- 多语言支持:在处理中英混合内容时表现优异,适合国际化团队的协作场景
- 响应速度:相比 Claude Opus 4.6, Gemini 3.1 Pro 的响应延迟更低,交互更流畅
局限提醒:
- 事实幻觉:虽然基准测试成绩优秀,但在处理 2025 年之后的最新信息时仍可能出现幻觉,建议配合搜索验证
- 创意写作:在需要强烈个人风格或情感共鸣的创意写作场景下,Claude 的表现往往更有「温度」
- 复杂代理任务:当需要模型自主执行多步骤、多工具协同的复杂任务时,Claude 的可靠性更高
四、为何 Gemini 3.1 Pro 代表未来方向
当业界还在争论「代码能力更重要还是推理能力更重要」时,Gemini 3.1 Pro 用「我全都要」的姿态给出了另一种答案。这种「六边形战士」式的发展路线,可能代表了 AI 模型的下一阶段演进方向。

4.1 从「偏科生」到「全能型」的进化逻辑
回顾 2023-2024 年的大模型竞争,我们见证了一系列「单点突破」:
- GPT-4 凭借推理能力确立领先地位
- Claude 以长文本和安全对齐见长
- 各类代码专用模型在编程任务上各显神通
这种分化有其历史必然性——在模型能力快速迭代的早期,聚焦特定场景确实能带来更快的进步。但当基础模型能力达到一定阈值后,「切换成本」开始成为用户体验的瓶颈。
想象一个典型的知识工作者一天的任务流:
- 上午:分析行业报告(需要长上下文)+ 提取数据洞察(需要推理能力)
- 下午:编写代码实现数据可视化(需要代码能力)+ 制作演示 PPT(需要多模态)
- 晚上:撰写项目总结(需要写作能力)+ 与团队讨论(需要对话能力)
如果每个任务都需要切换到不同的「专用模型」,这种碎片化体验会严重拖累效率。Gemini 3.1 Pro 的价值在于:一个模型覆盖 80% 的场景,且每个场景都能达到「良好」以上的水准。
这种「全能型」路线不是对「专用型」的替代,而是对主流需求的重新聚焦。对于大部分用户而言,「够用且全面」比「极致但单一」更具实用价值。
4.2 对 AI 应用开发者的启示
对于构建 AI 应用的开发者和产品经理,Gemini 3.1 Pro 的发布释放了重要信号:
1. 多模态不再是「加分项」,而是「基础项」
Gemini 的原生多模态架构证明,图像、视频、音频的理解能力可以与文本能力同等强大。未来的 AI 应用默认应该具备「看懂世界」的能力,而非仅靠文本描述。
2. 长上下文将重新定义交互范式
200 万 token 的上下文窗口意味着「对话即数据库」——用户不再需要精心设计提示词来「塞进」所有背景信息,而是可以直接上传整个项目资料、历史对话记录、参考文档,让 AI 在完整语境中工作。
这催生新的交互模式:
- 持续对话工作流:一个项目在一个对话中完成,AI 始终掌握完整上下文
- 知识库即插即用:将企业知识库直接作为对话背景,无需复杂的 RAG 搭建
- 跨会话记忆:AI 可以「记住」数周前的讨论内容,形成真正的长期协作关系
3. 综合能力比单项冠军更适合 B 端场景
企业级应用的核心诉求是「稳定可靠」,而非「某一方面的惊艳」。Gemini 3.1 Pro 在各维度的均衡表现,使其更适合作为企业 AI 基础设施的底座。
4.3 对行业竞争格局的影响预判
Gemini 3.1 Pro 的发布可能加速以下几个趋势:
趋势一:「综合能力」成为新的竞争维度
预计未来 12 个月内,我们将看到更多模型主打「全面性」而非「单点突破」。Claude 和 GPT 系列很可能会在下一代版本中强化多模态和长上下文能力,缩小与 Gemini 的差距。
趋势二:模型选择逻辑从「选最好的」变成「选最适合的」
用户不再只看基准测试分数,而是综合考虑:
- 与现有工作流的整合程度(Google Workspace vs Office 365 vs 其他)
- 定价策略和性价比
- 特定行业/场景的优化程度
- 数据隐私和合规要求
趋势三:「模型即平台」生态的深化
Google 拥有从搜索、邮件、文档到云服务的完整生态,Gemini 3.1 Pro 的全面性使其能够无缝嵌入这一生态。相比之下,OpenAI 和 Anthropic 更依赖第三方集成。生态整合能力可能成为下一个竞争焦点。
趋势四:垂直领域「专用模型」的细分机会
当基础模型解决「通用能力」后,金融、法律、医疗、教育等垂直领域的「专用模型」将迎来机会。这些模型不需要在通用能力上与 Gemini 竞争,而是专注于特定领域的知识深度和合规要求。
4.4 一个大胆的预测
Gemini 3.1 Pro 可能标志着 AI 模型竞争进入「后基准测试时代」。
未来的竞争重点将从「跑分」转向:
- 实际使用体验:响应速度、交互流畅度、错误恢复能力
- 生态整合度:与现有工具链的无缝衔接
- 成本效益:在可接受性能下的最低成本
- 可控性:模型行为的可预测性和可配置性
五、总结与建议
5.1 核心观点重申
Gemini 3.1 Pro 的价值不在于它是某一领域的「最强」,而在于它是当前唯一一个在推理、代码、多模态、长上下文、代理能力等所有关键维度上都达到第一梯队的模型。
在 Humanity’s Last Exam 上,它以 44.4% 的成绩领先 Claude 和 GPT;在多模态和长上下文上,它的原生优势几乎无法撼动;即使在代码和代理任务上略逊于专用模型,其差距也在可接受范围内。
这种「六边形战士」的综合实力,使其成为当前最符合「通用 AI 助手」定位的模型。对于不确定今天会面对什么任务的用户,选择 Gemini 3.1 Pro 意味着不需要在能力之间做取舍。
5.2 适合使用 Gemini 3.1 Pro 的场景
强烈推荐:
- 跨领域知识工作者:需要同时处理文档分析、数据分析、内容创作、代码编写的综合岗位
- 多模态内容创作者:经常需要处理图像、视频、音频素材的创作者和运营人员
- 长文档处理需求:法律、金融、咨询等需要频繁分析长篇报告的行业
- AI 应用原型开发:需要快速验证多模态 AI 应用概念的开发者
谨慎考虑:
- 专业软件工程团队:如果核心需求是大型代码库维护和重构,GPT-5.3-Codex 或 Claude 可能更合适
- 高 stakes 的专业决策:医疗诊断、法律意见等需要极高准确度和可解释性的场景,建议使用专用模型或多模型交叉验证
- 强创意写作需求:小说、剧本等需要强烈个人风格的创作,Claude 的「温度」可能更受欢迎
5.3 使用建议
- 充分利用长上下文:不要害怕上传大文件,让 Gemini 在完整语境中理解任务,而非过度压缩提示词
- 多模态是核心优势:遇到「文字难以描述」的需求时,直接上传截图、设计稿、视频片段
- 事实核查仍是必须:虽然基准测试成绩优秀,但在处理 2025 年后的事件或数据时,仍建议配合搜索验证
- 与专用模型搭配使用:将 Gemini 3.1 Pro 作为「主力模型」,在特定场景下(如复杂代码调试)切换到专用模型
5.4 未来个人观点
Gemini 3.1 Pro 的发布可能是一个转折点——AI 模型竞争从「单项冠军赛」进入「全能锦标赛」。未来的模型不再追求某一维度的极致,而是在保持全面性的基础上寻找差异化优势。
对于用户而言,这是好消息。当所有主流模型都达到「良好以上」的水准时,选择的重点将从「哪个模型更强」转向「哪个模型更适合我的工作流」。
2026 年 的 AI 竞争,才真正开始有趣起来。
作者:Snoopy_hui
扫一扫 微信咨询

商务合作 联系我们
 微信扫一扫
微信扫一扫 



