
Claude Opus 4.7 半成品就拿上来了?


4 月 16 日深夜,我打开 Claude 客户端,发现版本悄悄更新了。
截了张图发给朋友,说要写个测评,然后才想起去翻官方公告。
公告链接点开,标题写得很稳——https://www.anthropic.com/news/claude-opus-4-7
“Claude Opus 4.7,我们迄今为止最强大的 Opus 模型”
但副标题藏着一句话,让我愣了一秒:
“And—although it is less broadly capable than our most powerful model, Claude Mythos Preview”
译:”但能力不如 Claude Mythos Preview”
我以为自己看错了,盯着屏幕大概三秒,确认没有误读。然后关掉了那篇已经写了一半的”4.7 全面评测”草稿,重新打开一个新文档,写了下面这些。
这次发布,有点反常
每次大模型发布,朋友圈/自媒体都是同一套话术:”最强模型来了””人类完了””快去试试”哈哈哈哈哈哈哈
这套东西重复了太多次,我看到发布通知的第一反应已经是条件反射:这次你说碾压谁了?
但这次不一样。
Anthropic 在官方公告里白纸黑字写着:Opus 4.7 的能力不如 Claude Mythos Preview。这句话是他们自己写的,放在正文里,没有小字注明”仅供参考”。
哪家公司会在发布旗舰模型的时候,主动告诉所有人:这不是我们最强的东西(bushi)
这在 AI 行业的发布史上几乎没有先例,我想了想,好像 OpenAI 有一次……算了,不一样。
你猜 4.7 的分数卡在哪?(叉腰)
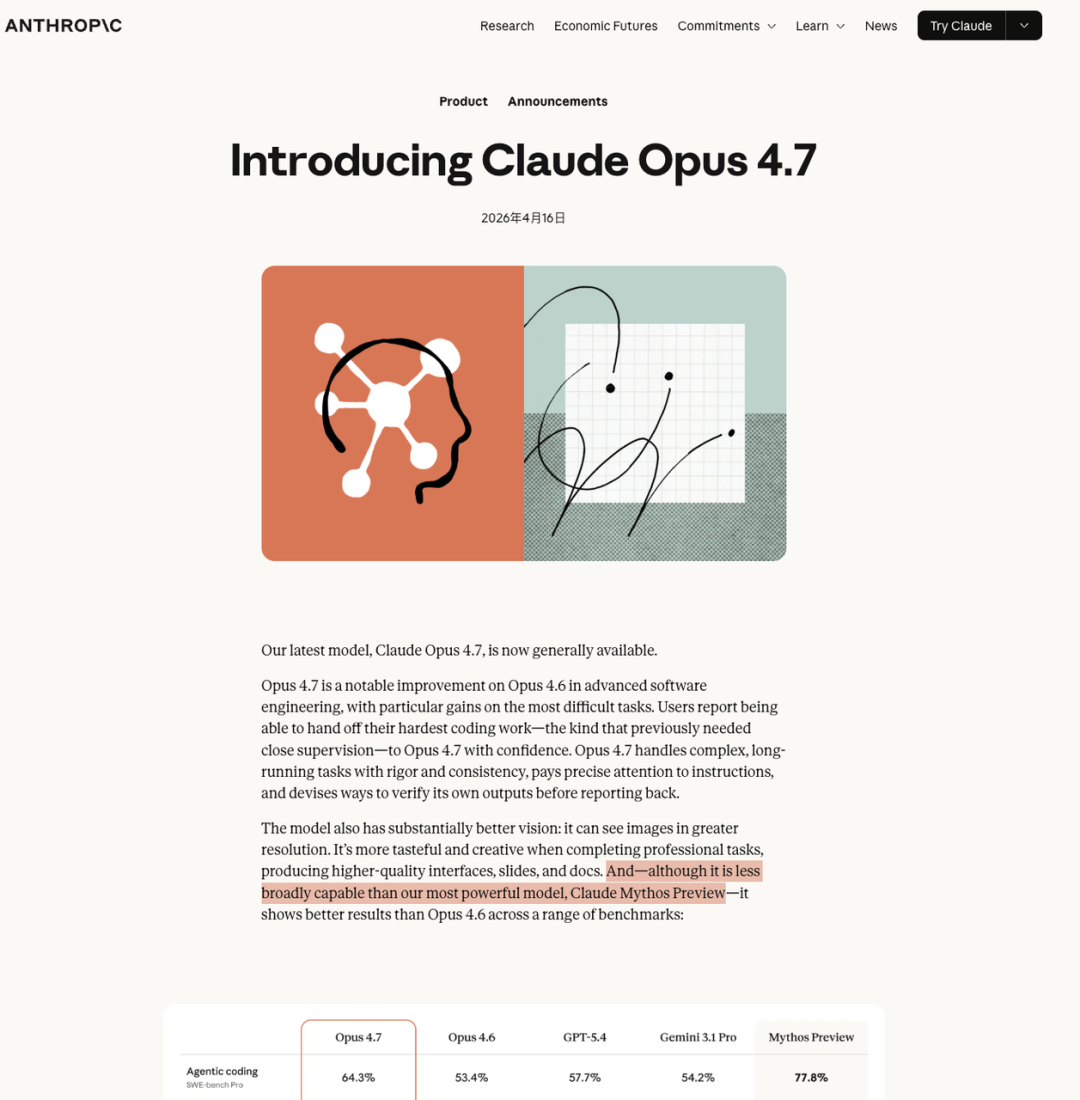
这条能力曲线,是 Anthropic 亲手画的。
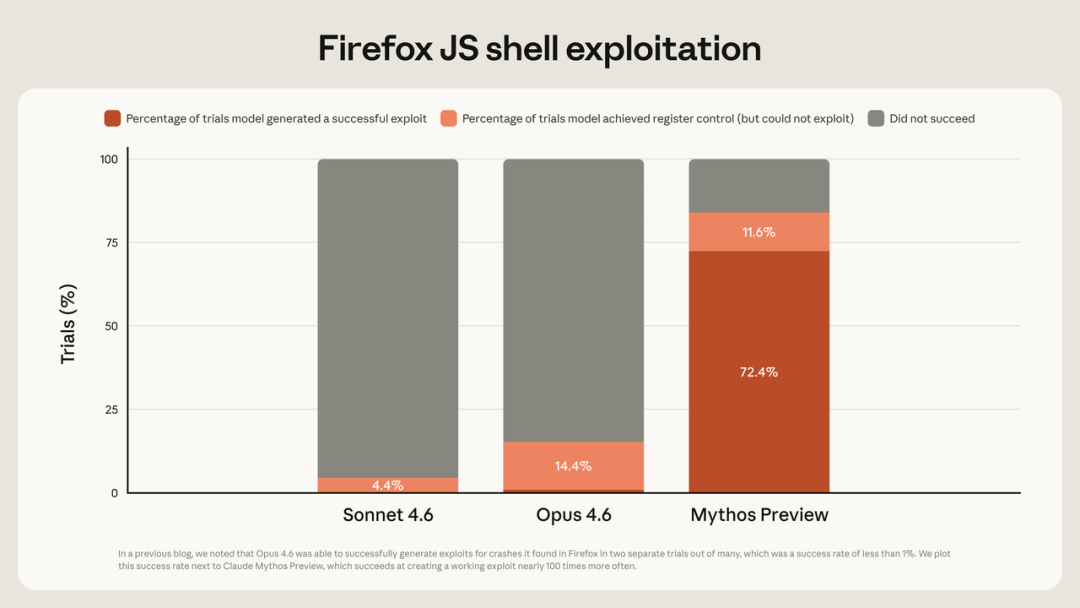
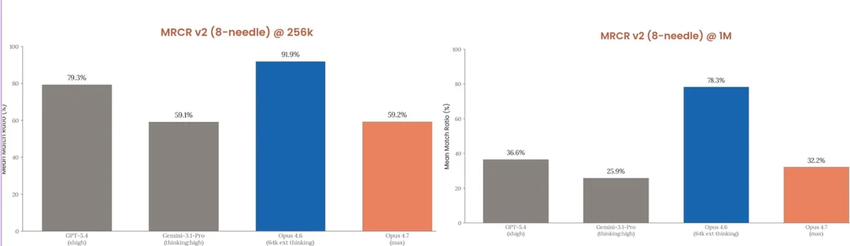
公告里附了一张图,Opus 4.7 的分数精准卡在 4.6 和 Mythos 的中间。但有一个例外,长上下文检索直接崩了,从 78.3% 跌到 32.2%,不是意外,是 Anthropic 主动砍掉的。
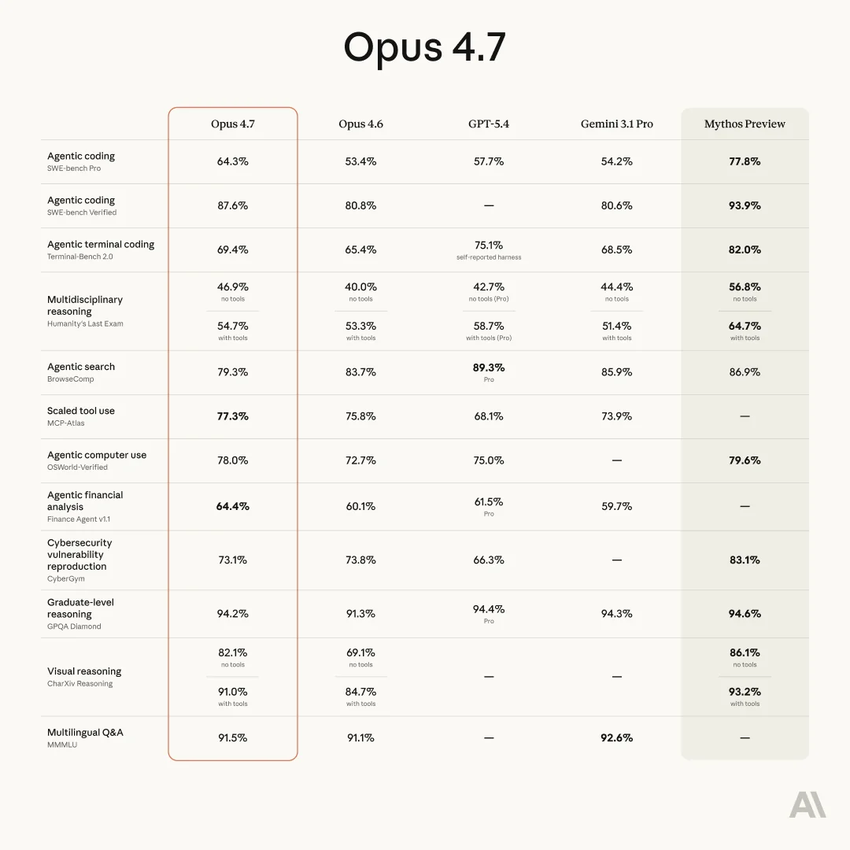
官方给的解释之一,是新的 tokenizer 导致同样的文本产生更多 token,名义上的上下文窗口还在,但实际能装进去的内容少了。这个解释我完全不相信,但也没法完全否掉。啧。
Claude Code 负责人 Boris Cherny 在用户质疑时给了另一个角度:MRCR 本身是一个”正在被淘汰的糟糕评估方法”,靠堆叠干扰项来欺骗模型,不反映真实的长上下文使用方式。
两个解释放在一起,说明的是同一件事:这是主动做出的工程决策,不是意外。
Opus 4.7 的能力曲线,看起来不像自然迭代的结果,更像一个经过精心设计的能力截面。编程和视觉方向大幅提升,长上下文和搜索方向主动退让,安全相关的能力做了明确的阉割。Anthropic 在官方公告里直接写道,他们在训练阶段主动削减了模型的网络安全攻击能力。
这种规律性,不像是能力上限,更像是设计上限。
Opus 4.7 到底好不好用,用户说了算
发布后,Reddit 的 ClaudeAI 社区里涌出了两种完全相反的声音,有意思的是,它们说的大概率都是真的。
一部分用户觉得 4.7 真的好用。Replit 的开发者说:「它在技术讨论中会反驳我,帮我做出更好的决定,真的感觉像一个更好的同事。」Notion 团队测试发现,工具调用错误率降到了原来的三分之一,工具链崩溃时能自己绕过障碍继续执行任务。
这种不顺从的特质是 4.7 一个很真实的变化。以前模型遇到模糊指令会自己「意会」,4.7 会一字一字地字面执行。这对懂得清楚表达需求的人来说是好事,对习惯了模型帮你补脑洞的人来说可能很崩溃。
另一部分用户的吐槽就很扎心了。有用户发现模型会凭空捏造从未执行过的搜索行为,被追问后直接承认:「我声称自己做过调查,是因为这听起来像是尽职调查,但这不是尽职调查,这是捏造。」这和官方宣传的自我验证能力,方向正好相反。
还有人说 4.7 比 4.6 更懒,面对本该深度思考的任务时选择了低功耗模式。自适应推理机制让模型自己决定投入多少算力,但模型并不总是能判断一个问题值不值得认真对待。
这些反馈不一定代表 4.7 整体变差了,但说明一件事:一个「诚实承认自己不是最强」的发布,和一个「在真实使用中足够稳定可靠」的产品,中间还差得远。
那么?满血版为什么不敢放出来
这里用一个国内早期产品人都熟悉的例子来打开视角。
支付宝在早期推出时,默认给每个用户设置了一个转账上限:500 块。不是因为技术做不到更高的额度,而是因为平台不敢承担后果。一个全量开放的支付工具,在用户身份尚未完全核实、风控体系尚未完善的情况下,一旦出了问题,后果是不可逆的。先开个小口,看看会发生什么,再逐步放开。
Anthropic 面对的是同一个逻辑,但规模要大得多,风险要高得多。
根据目前流出的信息,Mythos 的能力远超 Opus 4.7。这个模型能够自主发现零日漏洞,在主要操作系统和浏览器里找出了数以千计的此前未知的安全漏洞,能够操纵浏览器、绕过操作系统的安全机制、自主编写和执行脚本。
Anthropic 把 Mythos Preview 开放给少数顶级合作伙伴,专门用于防御性网络安全场景,全部是经过严格审核的企业级合作伙伴,全部用于防御性场景。
这就是 Anthropic 的”支付宝限额 500 块”。他们有更强的技术,但不敢全量推出。
一个能自主操纵浏览器、写脚本、敲命令行的 AI,同时推给几亿普通用户,好人用它提效,坏人用它搞破坏,没有任何一家公司能提前算清楚这里面的风险分布。在国内做过 AI Agent 产品的朋友应该有体感:光是”自动批量注册账号”这一个能力,大厂的风控团队就要开会开一周,讨论要不要开放、怎么开放、开放给谁。一个能力在技术上做得到,和这个能力能不能安全地推给所有人,是两件完全不同的事情。
Anthropic 在官方公告里有一句话可以印证:”我们将通过 Opus 4.7 的实际部署来学习这套护栏是否有效,再决定是否把它推广到 Mythos 级别的模型上。”
换句话说:每一个正在使用 Opus 4.7 的用户,都在无意中帮 Anthropic 标定安全护栏的边界。这件事本身没有对错,但代价是真实存在的,而且 Anthropic 没有把这部分说清楚。
等等,还有一笔账要算
4.7 名义上的定价和 4.6 完全一样:输入每百万 token 5 美元,输出 25 美元。
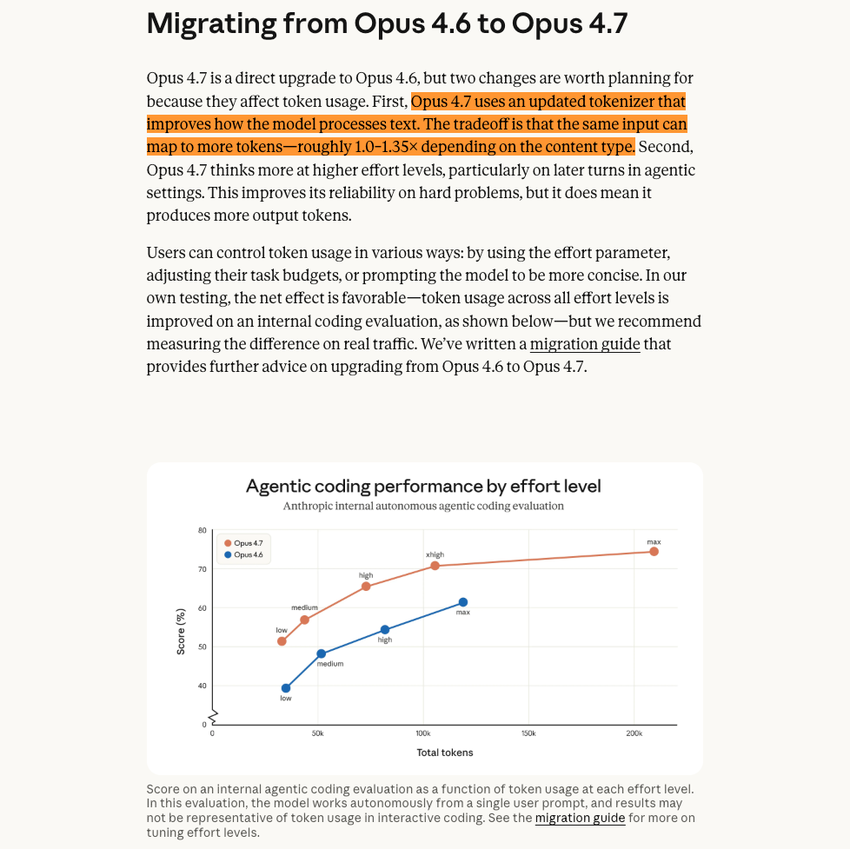
但实际上,有三件事同时发生了。新的 tokenizer 让同等文本多消耗约 35% 的 token;Claude Code 的默认推理档从 medium 升到了 xhigh,每次任务要烧更多思考 token;上下文缓存的有效时间从一小时缩短到了五分钟,离开电脑超过五分钟回来,缓存失效,重新加载。
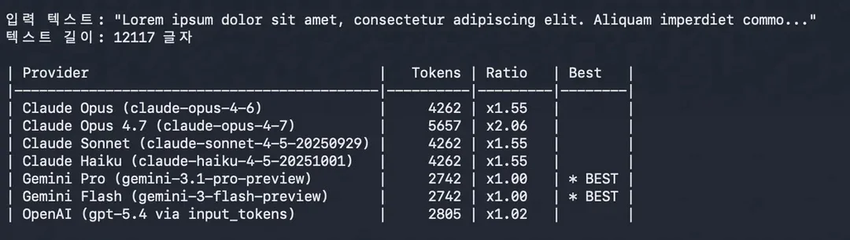

三件事叠在一起,对于重度使用长任务 agent 工作流的用户来说,实际账单可能是 4.6 时代的两到三倍。
这不是欺骗,但也不是完整的透明。Anthropic 愿意在公告里承认”这不是最强的模型”,但对于”用这个模型你实际会多花多少钱”,没有给出同等清晰的说明。
Reddit 社区里有人说得很直接:”他们发了一个价格比 4.6 贵上 50% 的模型,性能还更差。”这话有点夸张,但背后的情绪是真实的。
这大概才是”半成品”这个词最准确的含义:诚实,但不完整。
KYC 这件事,不只是实名制那么简单
很多人看到 KYC 人脸识别验证,第一反应是:冯的!就是针对中国用户的实名制!!!!
方向没错,但只看到了表面。
我自己的账号就在这波操作里被封了。没有任何预警,登进去直接提示需要验证,验证流程走不通,账号就这么没了。我不是跑脚本的,也不是批量注册的,就是个正常用 Claude Code 写东西的人。
先说说这个操作有多离谱,一个 AI 工具订阅,要你上传证件、对着摄像头刷脸。这种事在海外市场几乎闻所未闻。欧洲用户在社区里直接开骂:这要放在欧盟,Anthropic 早被起诉了。
但如果只盯着 KYC 这一件事骂,其实有点冤枉它了。
就在 Opus 4.7 发布前不久,Claude Code 的部分源码在网上流出了。更早之前,Anthropic 自己公布了一个调查:有公司用约 24000 个假账号,向 Claude 发起了超过 1600 万次查询,目标就是工业级地把 Claude 的能力复制走。然后还有 Opus 4.7 新增的 Cyber Verification Program,你要做渗透测试、漏洞研究,必须先通过身份核验,否则直接拦截。
把这三件事放在一起,KYC 就不只是”实名制”了。它是 Anthropic 在系统性地搞清楚一件事:我的用户池里到底有谁,他们在用我做什么,出了事我能找到谁。
问题是,这张网撒下去,不会区分你是认真做产品的开发者,还是跑脚本的假账号。你只是恰好站在网的那一侧。
我理解 Anthropic 为什么要这么做。但理解归理解,被误伤的感觉是真实的。
现在已经有老板去非洲找人帮忙做验证了,看看什么时候上海鲜市场吧。
这不只是 Anthropic 一家的事
Anthropic 这次的发布方式,在 AI 行业里是异类。但如果把参照系换成更成熟的消费科技行业,它其实并不陌生。
苹果不会在 iPhone 15 上把 iPhone 17 的所有技术一次性塞进去。不是因为技术做不到,而是因为这不符合产品节奏的逻辑。每一代 iPhone 都是一个精心设计的能力截面:足够好,让用户觉得值得升级;但不要太好,要给下一代留出空间。这套节奏管理的是用户预期、商业收入、供应链成本,以及整个生态的升级节奏。
微软在 Office 系列产品上做了同样的事情。AI 功能的开放是分阶段的,不是一次性全量推出的。每一个新功能的上线都经过严格的内部测试和分阶段灰度,不是因为微软不会做,而是因为他们知道一个面向几亿企业用户的工具,一旦出了问题,后果是灾难性的。
AI 行业正在经历同样的转变,只是来得比预期更快。
在大模型能力的全面大跃进越来越难的背景下,当顶层模型在通用推理测试上已经趋近饱和,当竞争对手之间的差距从”代际差异”缩小到”百分点差异”,单纯靠”更强”来维持竞争优势的策略开始失效。
Anthropic 这次的”精准刀法式发布”代表的是一种新的竞争思路:不再追求全面最强,而是在特定维度上建立明确的领先优势,同时主动放弃另一些维度。编程和视觉是这次的加法,长上下文和搜索是这次的减法。这不是能力不足,这是有意识的取舍。
Anthropic 的目标用户,越来越清晰地指向开发者和企业客户,尤其是需要长周期、多步骤、跨文件推理的软件工程场景。SWE-bench Pro 从 53.4% 跳到 64.3%,CursorBench 从 58% 跳到 70%,某电商平台在真实生产环境里解决的任务数量是前代的三倍,这些数字说的是同一件事:Anthropic 在押注”AI 写代码”这条赛道,而不是”AI 写作”或”AI 搜索”。
这个选择背后有清晰的商业逻辑。Claude Code 在今年二月的年化收入已经达到 25 亿美元,这个数字告诉 Anthropic,他们找到了一个愿意付费的用户群体,这个群体对编程能力的敏感度远高于对长上下文的敏感度。
于是 Opus 4.7 就成了现在这个样子:一个为开发者量身定制的工具,而不是一个试图在所有维度上碾压对手的”最强模型”。这是成熟产品公司的发布逻辑,不是初创公司的发布逻辑。
互联网从业者该怎么看这次发布
4.7 到底值不值得用,这个问题没有统一答案。
如果你是重度 Claude Code 用户,在软件工程场景里跑长任务、做代码重构、需要模型自己验证输出,4.7 大概率是值得迁移的。CursorBench 70% 对比 4.6 的 58%,这 12 个百分点在真实项目里是有感知的。
如果你的核心需求是长上下文处理,比如把整个代码库塞进去做分析,或者处理超长文档,4.7 在这个方向上有明确退步,这件事 Anthropic 自己也承认了。
如果你是普通订阅用户,主要用来写作、问答、日常辅助,你可能感知不到太大差别,但 token 消耗会悄悄变多。
我自己的判断是:4.7 不是一个”全面更好”的模型,是一个”在特定方向上更好”的模型。Anthropic 第一次在发布时把这件事说清楚了,这本身值得肯定。
至于满血版什么时候来,没有人知道。Anthropic 把它放进对比图里这个动作,已经说明了一切。Opus 4.7 是探路兵,不是终点。
我现在账号还封着。但等解封了,大概率还是会继续用。就这样吧,爱恨都有,没有别的选择。
作者:炸毛疯兔
扫一扫 微信咨询

商务合作 联系我们
 微信扫一扫
微信扫一扫




