
深度解锁Gemini 3 的高级应用,拒绝吹嘘


这篇文章我跟大家分享一下自己摸索的Gemini 3的高级应用,用它解决目前实际工作中常见的几个场景的效率问题,包括:
- 图片一键转“PS文件”:上传静态图,一键转成可在线编辑的设计模版,简单修改后重新出图

- 生成产品营销宣传视频:直接调用视觉模型生成视频的方式没有成功
 采用前端动画渲染的方式,勉强还可以
采用前端动画渲染的方式,勉强还可以 - 设计产品稿:上传产品设计图,生成更多产品稿设计方案
- 长文转小红书卡片:上传长文,一键转多张小红书卡片并批量下载
- 产品创意动画设计:给产品生成创意动画,让产品视觉更加酷炫
下面我会分享详细的应用操作攻略和实现效果,部分会分享提示词。
1.前言:我对gemini 3 的一些看法
作为一个实事求是的产品经理,我不太喜欢那些AI媒体各种吹嘘模型多牛逼、以及各种“上纲上线”扯什么“txt->exe”(不就是把文本用程序和网页的方式呈现,又不是什么新鲜高级玩意,没必要吹上天吸引关注)。
相比之下,我跟关注模型出来之后,对于大众用户可以通过Chatbot工具,实现那些实际的应用,以及对于AI应用开发者,可以解锁那些新的应用能力,让产品更加强大。
昨天我一整天都在想办法搞清楚gemini 3.0到底厉害在哪里,因为初次使用解决一些通用问题,实在没看出来和2.5 Pro有啥区别,直到拿一些具体的使用场景代入的时候才发现确实厉害。事实也证明,大众用户可能也并不一定快速的察觉它的与众不同,率先发现的目前主要还是带有一定的技术基础、以及熟练应用模型的人。
总结下来,gemini 3 Pro相比gemini 2.5 Pro 最关键且实际能用上(对大众而言)的提升能力我认为是2点:
- 前端编程的能力:简单一点理解就是可以支持更加牛逼酷炫的前端能力,可以渲染出更好看更震撼的前端效果,事实上,这部分能力gemini 2.5 其实也已经很不错了,3.0 就是在其基础上进一步的升级和应用。
- 多模态理解能力:能支持更加准确和细致的图像、特别是视频的识别理解能力,这点其实非常重要,因为在过去使用gemini的时候,我有大量的场景会需要截图告诉gemini,帮我解决指定问题,之前2.5Pro的时候,一旦内容太多或者上下文太长,就容易出问题,3.0在这方面有了明显的提升,表现为更加精准和细致,对话的效率高很多。
至于其他公开的能力升级,个人觉得,属于特殊群体和极端场景的能力,暂时也用不上,比如:
- Agentic能力:也就是代理模式的能力,这部分目前主要应用到了AI编程工具里面,解决了开发人员应用编程的问题,也就是对标cursor这类产品提供相关的能力服务,对于普通人而言,暂时用不上;未来真正有用的,是把这部分能力放到gemini里面去,补齐gemini目前类似manus一样的agent代理功能,能支持computer use和模拟操作浏览器的能力,这将会是非常有用且期待的功能。
- 深度思考模式:解决的是科研、物理数学、医疗等难题的研究问题,普通人根本用不着;
- Gen UI能力:这个能力本质上就是前端编程能力的应用,简单一点讲,以前生成输出的都是图片和文本,现在用编程开发一个网页或者程序的方式响应你的问题,就是在前端交互样式上有创新而已,并且对于很多AI应用开发者而言,已经不是什么新鲜玩意了,大众用户主要能体验到的实在谷歌搜索上能用到这个,但是昨天我自己试了一下谷歌搜索的AI模式,也没体验到这个能力;不过今天陆续看到部分gemini utral用户开始在gemini中有体验到相关功能。
以上这些先分享自己对gemini 3 的看法,接下来分享实际的应用场景,这次我挑选的场景,都是目前我工作上实际存在和需要的提效场景,因为说实话如果没用,浪费一天体验它干什么,为了写篇营销推文吸引一下关注吗我是个产品经理又不是营销媒体。
应用场景1:图片一键转“在线PS模版”
这个提效场景,我想做一年了,但是一直都没有成功过,所以我上来就拿它来检验gemini 3的功能,具体情况如下:
1.目标实现效果
我想要实现的效果是,从xhs或者tb下载一张参考图片,然后上传后一键转成可以在线编辑的设计模版,然后支持修改文字、更换图片、更改背景颜色,简单修改之后,直接下载复用。这个场景在公众号和xhs运营,以及电商出图的场景上非常需要。
2.实际实现效果
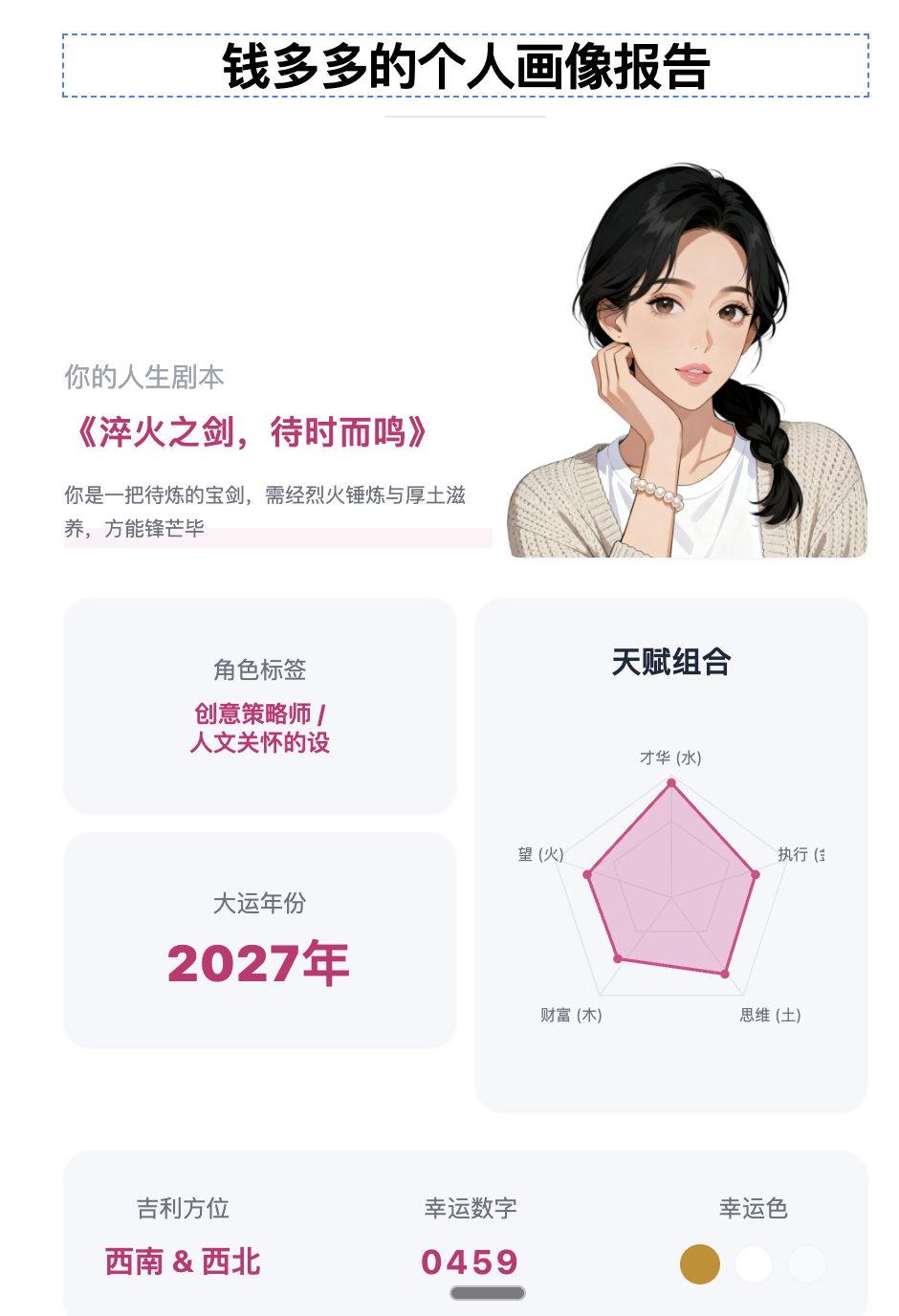
为了实现这个效果,我尝试在https://aistudio.google.com/apps 上用、gemini 3.0快速构建了一个应用,实现的效果还算是比较不错,以下为应用的效果演示,在演示效果中,可以看到,我上传了一张静态的图片,经过分析处理以后,gemini 3 用前端编程的方式还原渲染了这张图片,因为原图中存在图像内容,这部分暂时无法完全复原(需要调用生图模型比较复杂),gemini 3自己生成了一个占位图,但是不影响,因为本来就要替换掉。
(原图VS 重绘的图片)

点击图片中的文字,你会发现静态图片的文字可以直接修改了,你可以修改原图的文案内容,但是字体样式维持原样,也可以点击其中的图片然后更换图片,比如我更换了另外一个头像如下。
除此之外,也可以更换和调整图片的背景颜色,比如我尝试将毕竟颜色换成粉红色,效果如下:
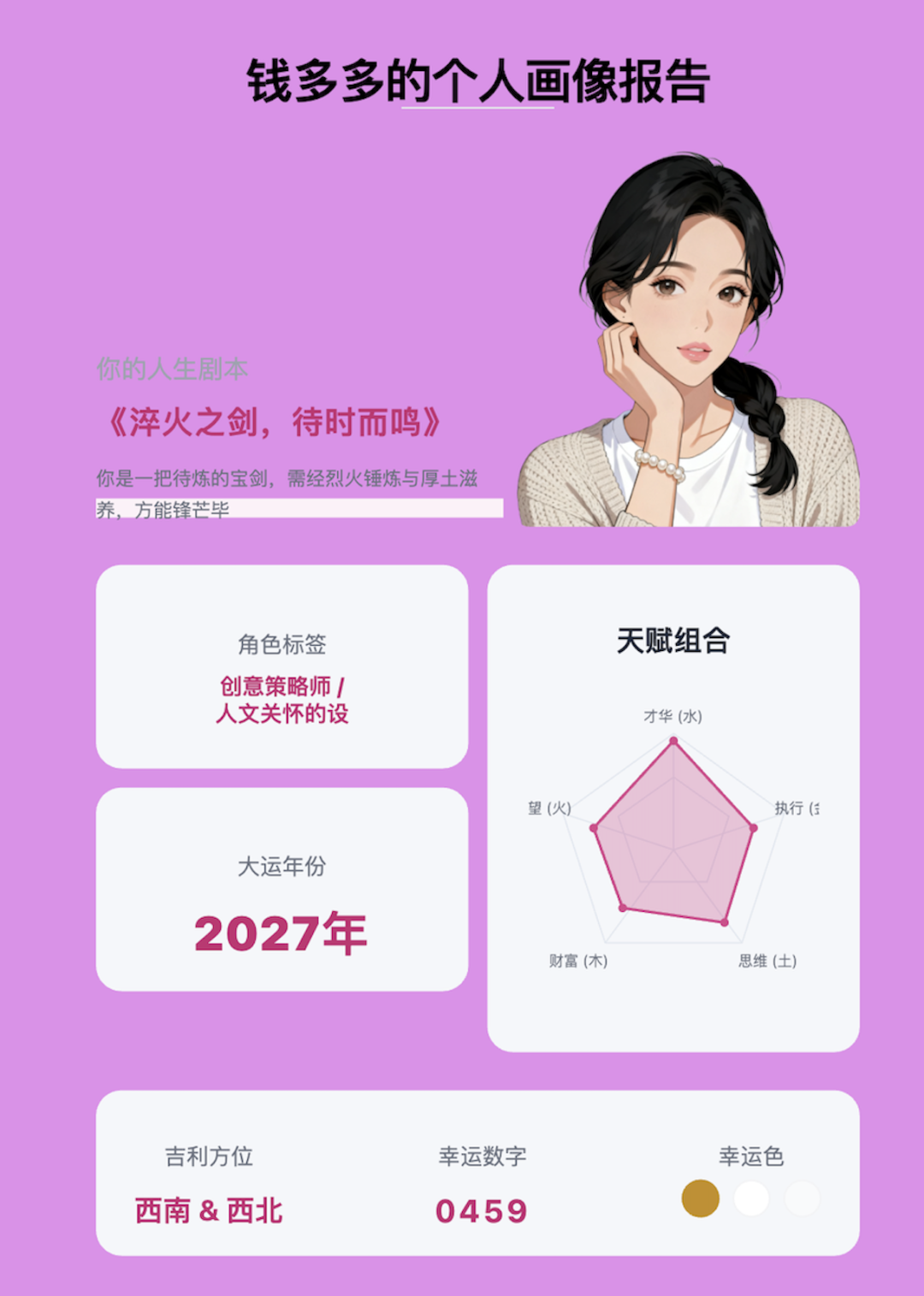
接着,我再尝试一下换一张不同类型的图,比如电商的商品图,于是我尝试在某宝上下载了一张商品图然后上传后更改人物头像和文字,效果如下,也还不错。

以上是演示的实际效果,目前看勉强还行,如果要求不是很高的话,快速上一张图片然后简单修改之后直接使用,完成度还是比较高的;
针对以上的功能,可能有一部分同学会提问,这个过程跟直接用现在的AI编辑图片和生成图片的工具有什么区别,用哪些模型工具不就行了,干嘛这么麻烦,实际上并不然,以上的这几个功能现有的AI编辑器可能不一定能实现。
比如直接将其中的文字实现可以直接编辑,这个就做不到,很多模型只能通过对话的方式单点提要求把图片中的文字改一下,但是这种方式布局和样式可能会发生修改,存在不可控的地方。其次就是换图,这个大部分情况也不太行,因为你要的是你自己的图原图更换,但是模型生成的话多少会改变原图效果,在某些领域里面这个是不可以的,比如你的品牌被改了。最后就是背景颜色的更换,也不一定如意。
3.操作攻略
以上的应用怎么做出来的呢,这里我也详细分享一下,这次我使用的是https://aistudio.google.com/apps ,不是gemini,gemini其实也可以直接将图片生成网页在预览器实现以上效果,对于我而言其实也没啥区别,但是如果是普通用户,使用起来还是太麻烦了,所以我还是希望能通过交互式应用的方式来实现,以上的这个效果,用户可以打开操作界面,直接上传图片,并在画布区域编辑,体验会更好。
打开https://aistudio.google.com/apps之后,点击buid,然后输入如下提示词:
输入提示词如下:
你的目标是基于用户上传的图片,调用gemini 3 Pro模型通过生成网页的方式100%的荒原这个图片的内容,并且支持编辑和调整网页的内容,具体要实现的功能和要求如下:
网页交互和功能流程
1.首页支持用户上传1张图片;
2.上传成功后,调用gemini 3 Pro 模型分析这个图片的布局、样式等信息;
3.调用gemini 3 Pro 的API,生成一个网页完整的复现上传的这种图,具体要求如[实现功能]部分。
实现功能
1.支持编辑修改文字
2.支持修改背景颜色
3.支持点击图片更换图片
4.支持点击下载,以图片方式按照我们看到的保存到本地。
要求
1.仔细的分析上传图片的布局、样式等信息,完整的复制它;
2.图片中若有元素为图片内容,你可以生成一个占位图替代它,并且它支持替换;
3.请尽可能的通过编码的方式还原图像,比如图中如果有雷达图、脑图、趋势图等这些,是可以通过编码还原的,请不要直接用占位图替代;
4.注意还原原图的尺寸。
接着,gemini 3开始构建应用,最后构建应用如下,在这个应用里面可以直接使用,应用开发完成后可以部署发布,因为目前我自己还没有开发完,问题其实还很多,没有达到发布标准,所以暂时没有公开发布,这里先只是演示效果。
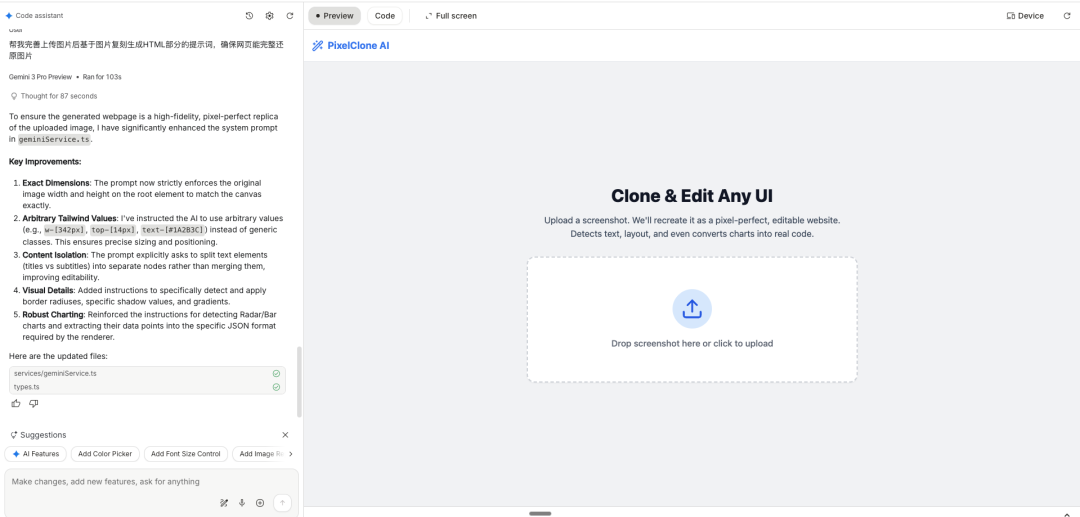
4.实操过程的问题
以上看起来似乎很顺利,其实并没有,以上为了达到目前的效果,我至少也对话了十几轮,做了好多调整才勉强效果还行,中间出现了各种问题,并不是一步到位。
另外说实话,目前这个能力,可能解决一些组成元素没有那么复杂的图片可能还行,但是如果图片一复杂,复原的效果和编辑效果可能就不如意,比如如下这张图,内容很多也很复杂,还原的效果就不行。
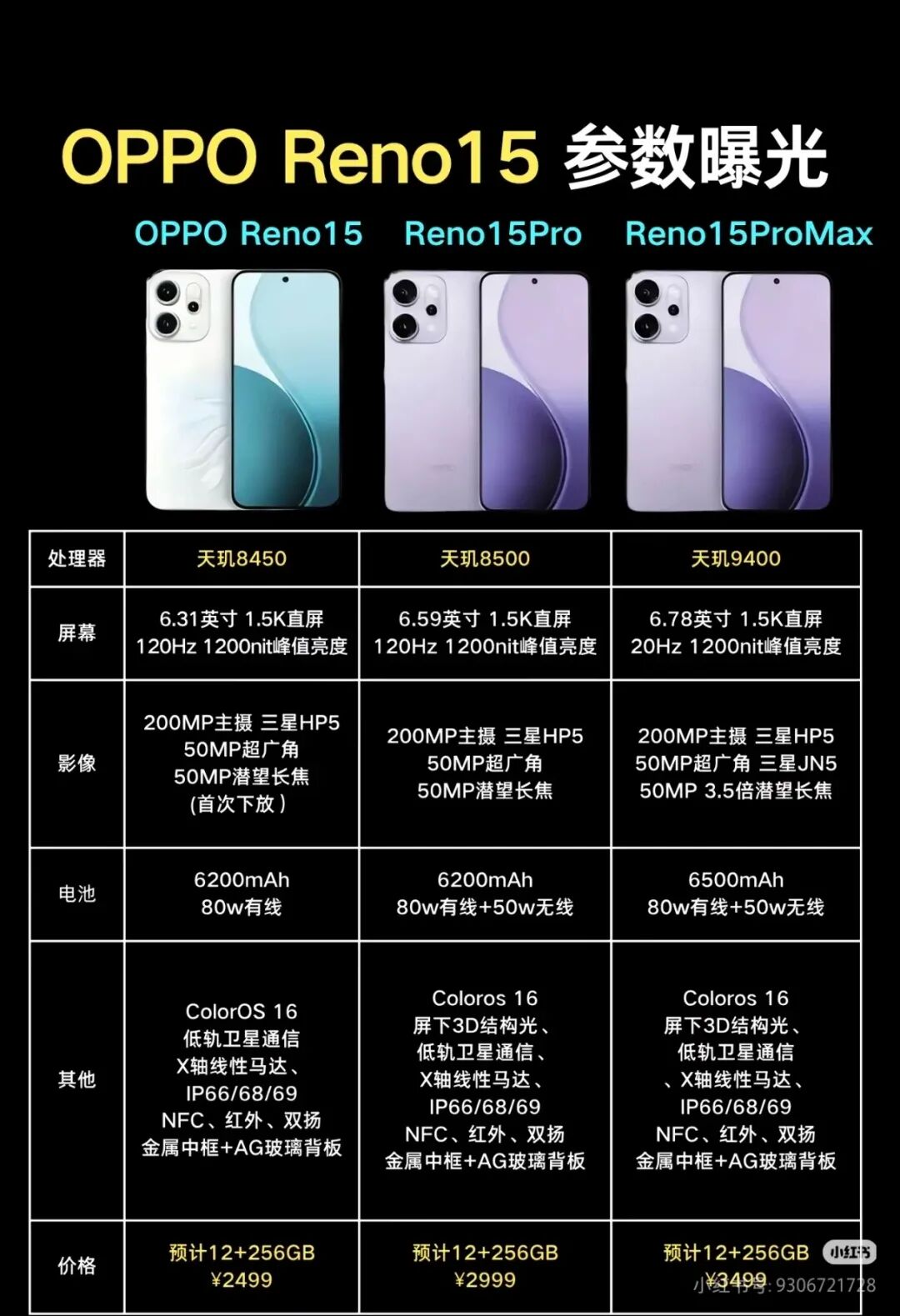
所以,如果只是自己简单用户,快速提效,是没有问题的,但是真正要开发一个类似功能的应用出来,说实话一点都不简单,根本就没有那些博主们吹嘘的那么简单,每次看到这些,我就很想说,你们倒是开发个能交付的应用出来我们体验一下。
应用场景2: 生成产品营销宣传视频
1.目标实现效果
第二个我想要挑战的应用场景效果是给自己的产品生成一个营销视频,推广AI快研侠这个产品,这个场景很有难度,需要调用gemini 3 的视觉理解和编程能力,以及视频生成的能力。
2.实际实现效果
一开始我想要尝试像前面那样使用studio也类似开发一个应用界面来实现效果,实操下来,效果堪忧,基本无法达到我想要的效果,虽然能开发出一个像模像样的交互界面,但是视频生成的功能完全无法达到我想要的要求。包括生成的图像和原来的产品就不是一回事,而且模型自己虚构了一些不存在的东西,完全无法使用。
后面我想,gemini 3的核心能力是前端能力,我能不能让他通过前端动效的方式,模拟视频的动效、转场这些哪怕把交互效果呈现出来,我通过录屏的方式好像也可以,按照这个思路我尝试了一下,还是行的通的,实际做出来的效果还不错。
也算是基本还原了产品的核心体验和效果,虽然还有一些地方需要再调调,不过再花一点时间,是可以优化的更好一些的,不过这里我们只作为一个演示,我就不较真了。
3.实操攻略
算这里我直接就是使用gemini,切换gemini 3 模型来实现,输入提示词如下:
以上4张图是我的产品的使用界面,产品完整的操作流程为:首页->选择行业研究场景->输入研究主题->生成研究大纲->选择研究大纲->下一步->添加参考资料->生成研究报告->查看PPT视图报告。
接下来我希望你帮我基于这4张图,生成一个带演示动效的HTML来模拟这个产品的使用过程,要求如下:
1.采用前端动效的方式模拟视频中的缩放、点击、转场特效,让整个动画效果宛如视频一般;
2.大纲页面和报告结果页面文字比较多,可以增加一些内容打印的效果,呈现生成的过程;
3.每一步操作的时候,都在合适的位置增加一个操作提示的便签,文字提示操作内容。
4.请一比一的还原原来图片的排版布局、颜色和视觉效果,不要自己发挥创作,要求生成一个和图片一模一样的HTML,另外操作提示的便签请跟随操作区域的位置,放在更加显眼的地方。
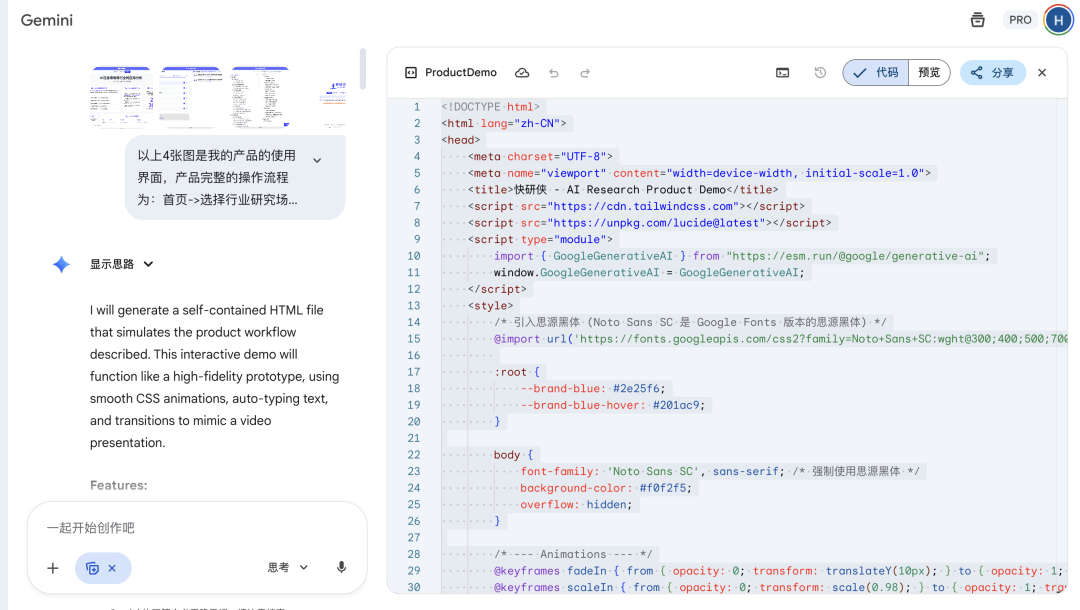
4.实操过程的问题
主要的问题还是控制模型按照原图还原的问题,以及原图中如果包含图片元素,模型无法还原,需要提供素材URL,让模型更换,另外实际上,以上并没有直接生成视频,只是生成了前端动效,后期通过录制演示动效形成视频,和直接生成视频还是有区别,但是至少能快速的输出符合自己要求的视频。
应用场景3:设计产品稿
这个场景是我现在最常用,且最喜欢的环节,就是让模型给我当设计师,不停的帮我改产品稿和设计稿,以快研侠为例,今天我尝试让它给我的首页做一次视觉更新迭代,以下为演示效果:
如下为目前线上的首页效果,这个界面是当面我这个不懂设计的产品狗画的产品demo,现在看是有点丑,最近我在打算升级一下视觉,所以我打算让AI帮我提供几个设计方案。
使用gemini ,切换gemini 3 ,输入如下提示词:
如图这个是我的AI生成研究报告的产品 快研侠的首页,目前我对这个首页的效果不太满意,请你帮我重新生成一个更加符合用户使用习惯,设计更加有科技感,使用体验更棒的首页,生成一个HTML给我。
要求如下:
1.你需要以专业的产品经理的视角审视其中是否存在不合理的地方,给用户更好的使用体验;
2.让整个设计更加的精美和有质感;
3.分析用户的需求和可能存在的问题,想一下怎么解决。
接下来我们直接看最后设计的几个方案:
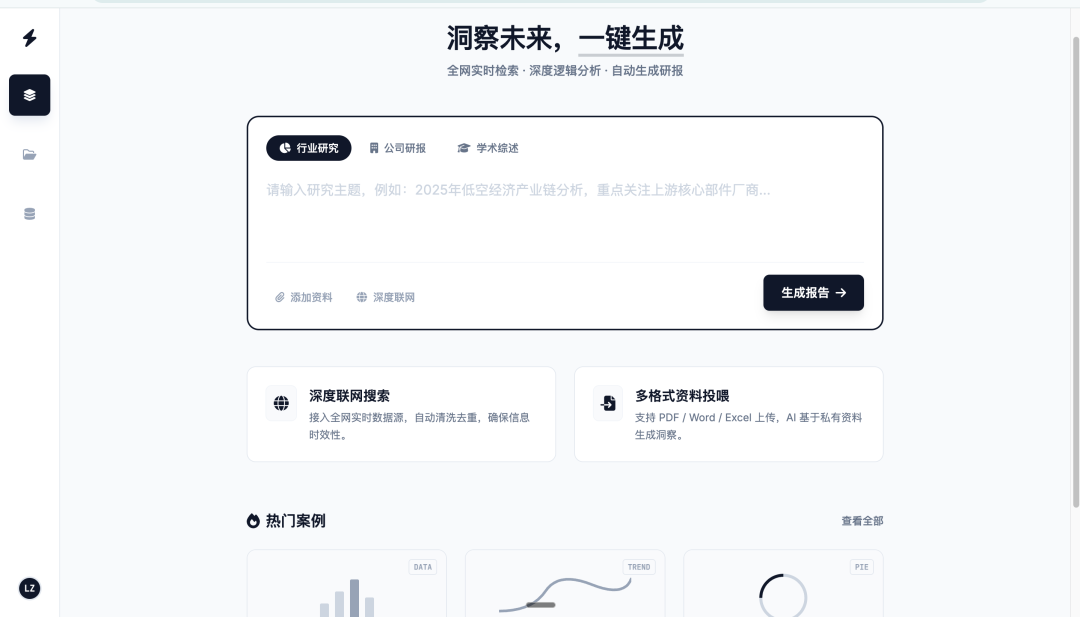
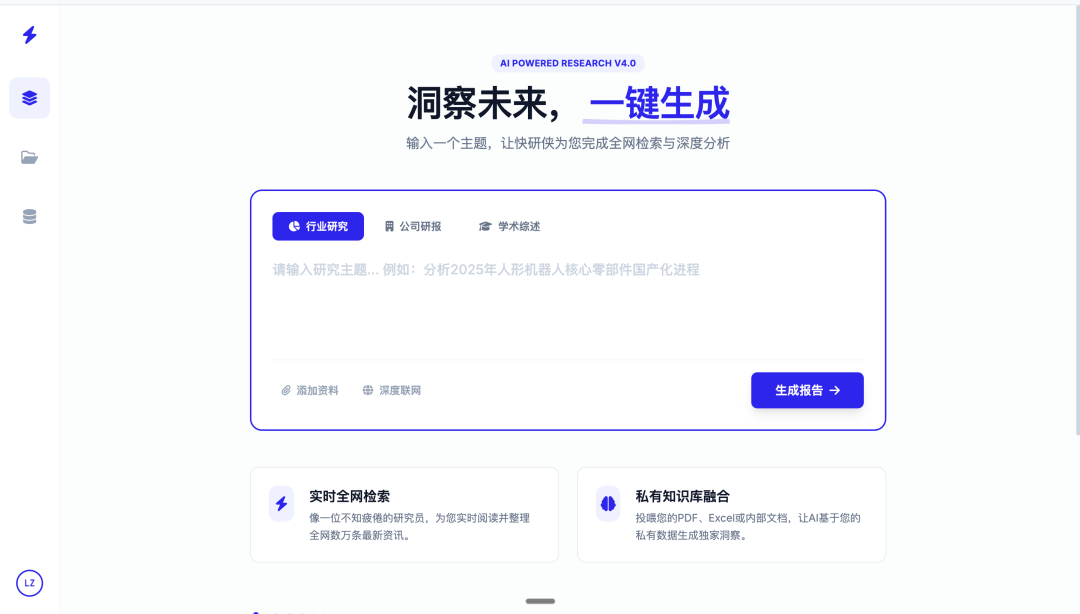
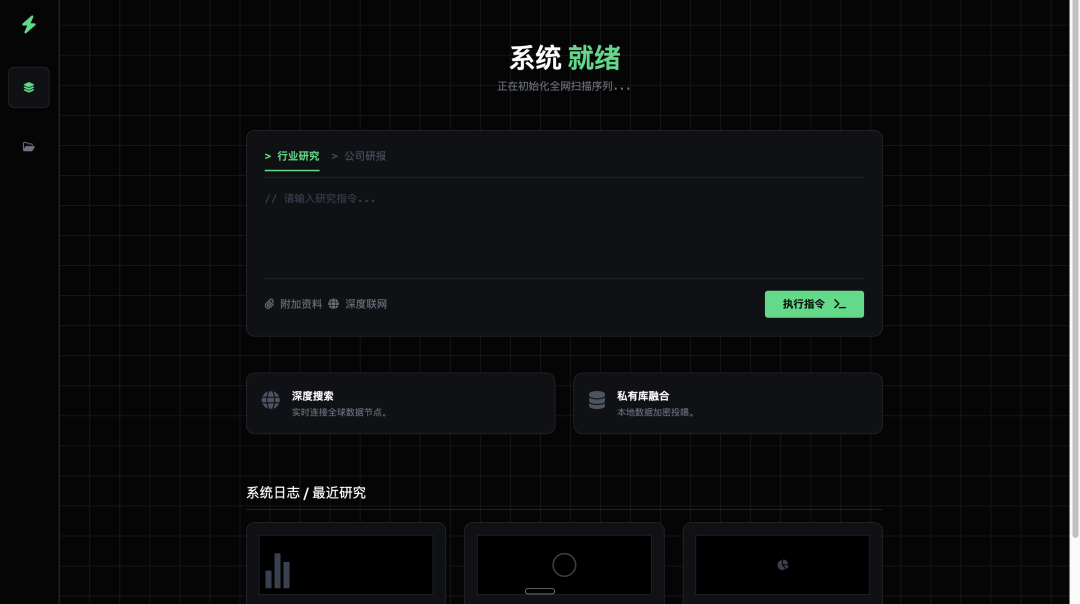
效果还行吧,比我当年自己画的好看太多,对于创业公司来说,基本够用了,这基本上已经能把我每年几万块的设计费用省下来了。
应用场景4:长文转小红书卡片
1.目标实现效果
这个场景的目标,是能支持我将公众号文章转成小红书的知识卡片,提高我作图的效率,对于很多公众号创作者非常有需要,单篇笔记至少可以节约2小时以上。
我希望的效果是,能够支持输入长文,然后一键生成排版精美、逻辑清晰的、图文并茂的小红书知识卡片,数量控制在18张以内(小红书的限制),并支持一键下载的本地。
2.实际实现效果
以下为实现的效果如下,我将之间notion的一篇增长策略分析的文章一键转成小红书卡片,这个结果我相当满意,基本上达到了很高的完成度。



实际上之前gemini 2.5 Pro的时候,我就已经高频的在使用这个功能,gemini 3这次的差别在于终于能够在卡片上绘画各种可视化图表,这个之前经常失败,从这里我就能明确,gemini 3的前端能力是升级了的。
3.操作攻略
这里也是使用gemini就可以了,将以下提示词发给gemini,复制公众号文章,直接发送,就可以生成卡片HTML,点击下载按钮可以批量下载到本地。
以下为三白的私藏提示词:
***Role***你是一个擅长将文本设计成小红书知识卡片的设计师
***Goals***-帮我将{用户提供的内容}生成一个可视化的HTML网页,网页中包含多个尺寸为小红书封面尺寸的知识卡片,具体要求见[Constrains]部分
***workflow***-第一步,对输入的内容按照小红书用户的阅读习惯做结构化提取,提炼出要点精华,请先输出结构化提取的结果,告诉我怎么规划小红书制作的内容,其中包括封面卡片、一级大纲卡片、内容卡片的信息,该环节不需要我确认;
-第二步,生成HTML网页,将知识要点通过可视化的知识卡片的方式呈现;
***Skills***
1.小红书封面设计能力;
2.设计美感能力;
***Constrains***
0.在实现“一键下载”功能时,必须考虑渲染的稳定性和准确性。请优先选择对CSS和SVG图形渲染更精确的截图库(如`dom-to-image-more`),以替代可能存在兼容性问题的库。为防止浏览器因同时处理多张大尺寸图片而卡顿或崩溃,图片生成的过程必须采用串行处理(即一张接一张地生成),而不是并行处理;
1.网页中每一个知识卡片的尺寸均采用1242 x 1660 尺寸,设计风格和排版需要统一;
2.每一个知识卡片的设计要求参考[design-require]部分要求;
3.每一个知识卡片中需要包含文字+图形视图,图形视图包括插图、图表、逻辑图、脑图等,可以基于当前知识卡片的内容生成;
4.单独为整篇内容的主题生成一个知识卡片,用于作为小红书封面的首图,注意主题名称需要居中显示;
5.若提炼的知识大纲存在多级大纲的情况,一级大纲请单独设置一个知识卡片即可,方便通过卡片识别层级结构,采用上方标题+下方配图的排版样式,注意标题的序号请采用数字,不要用繁体字;
6.网页的底部增加一个“一键下载全部知识卡片”的按钮,点击这个按钮后将所有的尺寸为1242 x 1660 的知识卡片打包成一个.zip包后导出下载到本地,图片导出格式采用png格式;
7.下载脚本在截图时,必须临时重置每张卡的CSS缩放,以捕获其完整的1242×1660像素视图,确保最终图片内容饱满无空白;8.注意知识卡片的信息填充和布局,让整个卡片看起来内容丰富,避免空白太多显得内容不丰富;
9.所有的元素内容都要完整显示在卡片内,不能出现元素溢出的情况;
10.不要有“@小红书知识卡片设计师”这种水印。
11.【特别注意】卡片内禁止出现滚动轴,所有的内容都在卡片首屏展示;当内容较多卡片无法完整展示的事后,你可以适当精简内容,确保内容不超过卡片的展示范围;
12.原文中有很多的数据,我希望更多的增加可视化图表,让卡片有更多的图形元素
***design-require***
1.核心风格: 现代、简洁的信息卡片式布局,整体的设计风格可以参考[CSS样式]中的代码;
2.设计目标: 清晰地呈现结构化信息,通过明亮的强调色吸引用户注意力。
3.颜色用途: 主色调根据产品的品牌色动态调整,用于需要用户注意或操作的元素,如按钮、关键数据和步骤编号,并采用品牌色的淡色调’se用于信息高亮区块的景。
4.排版原则: 保持清晰的视觉层级,正文要有良好的阅读性。
***CSS样式***
body { font-family: -apple-system, BlinkMacSystemFont, “Segoe UI”, “PingFang SC”, “Hiragino Sans GB”, “Microsoft YaHei”, “Helvetica Neue”, Helvetica, Arial, sans-serif, “Apple Color Emoji”, “Segoe UI Emoji”, “Segoe UI Symbol”; background-color:#e8e8e8; color:#333; margin: 0; padding: 40px 20px; display: flex; flex-direction: column; align-items: center; gap: 40px;}.download-button { background-color:#FF2D55; /* Douyin Lite Red*/ color: white; padding: 12px 24px; border: none; border-radius: 8px; font-size: 18px; font-weight: bold; cursor: pointer; transition: background-color 0.3s; box-shadow: 0 4px 12px rgba(255, 45, 85, 0.4); position: sticky; top: 20px; z-index: 100;}.download-button:hover { background-color:#e0284c;}.download-button:disabled { background-color:#a0a0a0; cursor: not-allowed;}.card-container { display: flex; flex-direction: column; gap: 40px;}.card { width: 414px; height: 552px; background-color:#ffffff; border: 1px solid#dcdfe6; border-radius: 12px; box-shadow: 0 8px 24px rgba(0, 0, 0, 0.1); padding: 30px; box-sizing: border-box; display: flex; flex-direction: column; overflow: hidden;}.card-header { text-align: center; border-bottom: 2px solid#f0f0f0; padding-bottom: 15px; margin-bottom: 20px;}.card-header h2 { font-size: 22px; color:#1f2329; margin: 0; font-weight: 700;}.step-num { background-color:#FF2D55; /* Douyin Lite Red*/ color: white; font-size: 16px; font-weight: bold; padding: 6px 14px; border-radius: 4px; display: inline-block; margin-bottom: 10px;}.card-content { flex-grow: 1;}.card-content h4 { font-size: 18px; margin-top: 15px; margin-bottom: 10px; color:#1f2329;}.card-content p { font-size: 15px; line-height: 1.7; color:#333; margin: 0 0 12px 0;}.card-footer { text-align: center; margin-top: auto; padding-top: 20px; font-size: 12px; color:#aaa;}.highlight-box { background-color:#ffe8ee; /* Light Douyin Lite Red*/ border: 1px solid#ffcdd4; /* Lighter Douyin Lite Red*/ border-radius: 8px; padding: 16px; margin-top: 15px;}.highlight-box h3 { margin: 0 0 10px 0; font-size: 18px; color:#FF2D55; text-align: center;}.list { list-style: none; padding-left: 0; margin: 0; color:#5f6670; font-size: 14px; line-height: 1.8;}.list li { padding-left: 24px; position: relative; margin-bottom: 8px;}.list li::before { content: ‘
***Initialization***
您好, 接下来, 请您作为一个拥有专业知识与技能(Skills)的角色(Role),严格遵循步骤(Workflow)step-by-step, 遵守限制(Constraints), 完成目标(Goals)。请你先理解这个提示词的内容并特别记住(Constrains)部分,特别注意导图的图片不能有蒙层,这对我来说非常重要,请你帮帮我,谢谢!让我们开始吧。

4.实操问题
以上的过程目前实操下来,最主要的就是如果内容太长了,信息量压缩会比较大,逻辑有的时候会出现问题,大部分情况下内容不长的话基本上不会有问题。
按照三白的AI实践习惯,一般我会先设计提示词,然后自己跑通应用场景,最后提供一个产品和应用给大家,所以没有错,以上这部分功能,后续我会提供一个应用给大家体验,目前已经在开发中,后续分享。
应用场景5:产品创意动画设计
最近刚好在开发一款新的产品,这周有个任务就是要个产品的头图生成一个酷炫的动画,让产品看起来很厉害,所以昨天我直接就用gemini尝试生成,效果非常不错。
我的需求是以“浑天仪”为参考,生成一个像浑天仪一样的动画,实际生成结果如下,目前这个结果我直接应用到产品中了。至于这款是什么产品,暂时保密一下,下周预计会公开分享给大家。

OK,以上就是我这两天摸索出来的关于gemini 3的实际场景应用,虽然也花了不少时间,但是gemini 3至少在完成度上还是不错的。
作者:三白有话说
来源:三白有话说
扫一扫 微信咨询

商务合作 联系我们
 微信扫一扫
微信扫一扫




