
Claude“开源泄漏”的真相与噪音


最近关于 Anthropic 的 Claude“开源泄漏”的讨论很热闹。
我综合看了一下,整体可以分几个层面来拆解。
一、先说“真假程度”
目前流传的信息大多是未经官方确认的泄露或二手消息。
很多所谓“开源代码”其实可能是:
- 早期版本 / 残片
- 推测性复现(别人自己仿写的)
- 经过修改的模型权重 / 接口层
真正完整、可用、可复现的 Claude 核心模型被“完全开源泄漏”的概率,其实不算高。
这次泄漏的真正技术原因
Anthropic 发布 Claude Code 的 npm 包时,把 source maps(.map 文件)一起发布了。
而 source maps 里包含未压缩源码(TypeScript / TSX)。
这是完全可能发生的工程事故,行业里并不少见。
简单说:
- 前端 / Node 项目 build 后会生成压缩代码 + .map 文件
- .map 文件本意是调试用
- 如果不小心公开 → 别人可以反推出接近原始源码
但 “等于完全开源 Claude”是严重夸大。
传播里最误导人的一句是:“基本等于把整个项目完整源码暴露了”
关键误区:Claude ≠ Claude Code
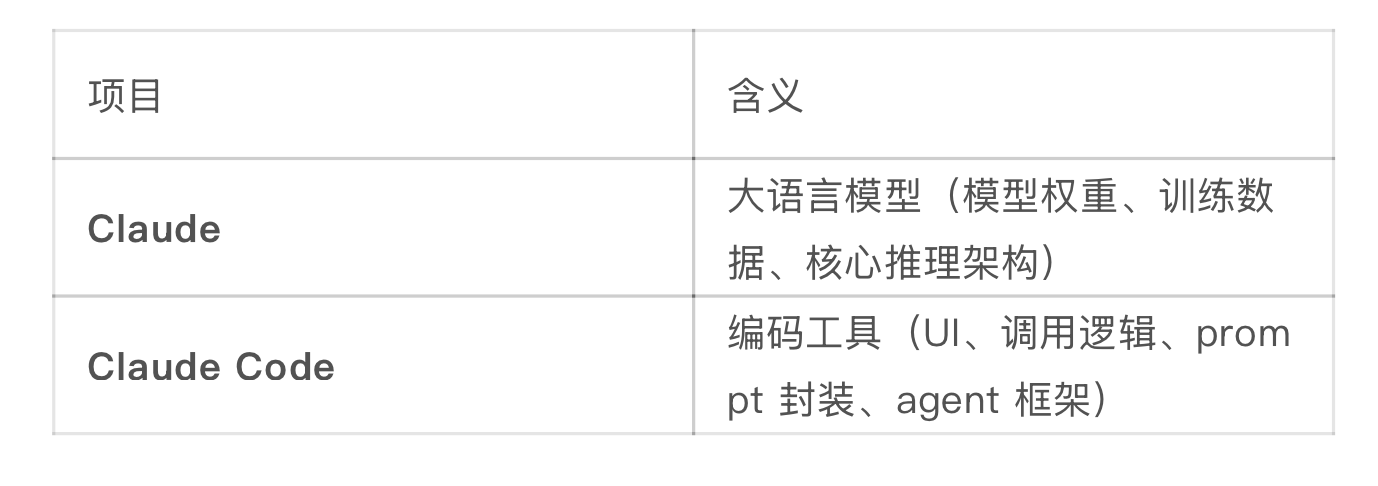
这次如果属实,泄漏的是:工具层代码
而不是:模型权重、训练数据、核心推理架构
二、如果部分属实,影响会在哪?
1)技术层面
- 可能帮助研究者更好理解类似 Claude 的架构和训练方法
- 加速开源社区(比如对标模型的发展)
2)商业层面
- 对 Anthropic 会有一定压力
- 但大模型的真正壁垒通常在:数据、训练规模、基础设施,不是单纯“代码”
3)安全层面
- 如果真有较完整能力外泄,可能被用于绕过安全限制
- 这是 AI 公司最敏感的一点
4)价值层面(对开发者真正有用的)
- prompt engineering(系统提示词设计)
- tool use / agent 调用方式
- IDE / coding agent 的交互逻辑
- Anthropic 的工程最佳实践
三、为什么这类“泄漏传闻”特别多?
因为现在 AI 行业有几个特点:
- 模型本身“黑箱”,外界很难验证
- 开源 vs 闭源竞争激烈(如 Meta 的 Llama 系列 vs 闭源模型)
- 社区很容易把“像 Claude 的东西”误认为“就是 Claude”
这次事件同时踩中了三个热点:
- 泄漏 → 情绪放大
- Claude → 顶级模型
- 开源 → 社区兴奋点
四、整体判断
更接近这样一个结论:
有噪音、有夸大,但未必有实锤级别的大规模核心泄漏。
即使真的有部分资料流出,也不太可能让别人“复制一个 Claude”。
大模型不是一个repo就能复刻的东西。
那么,对我们普通人或开发者来说,到底有多大价值?
这才是比泄漏更有意思、也更值得探索的地方。
五、对普通人或开发者的真实价值
其实在 Anthropic 的 Claude Code 里,最有价值的通常是:
- System prompt(系统提示词)
- Tool calling 规则
- 多轮推理结构(agent loop)
- 错误恢复策略(retry / fallback)
1)对普通用户
本质上是怎么把 Claude 用得更聪明。
但坦白说:对普通用户几乎没有直接用处。为什么?
- 普通人日常更多是输入 prompt 对话生成
- 泄漏的这些 prompt 往往是 IDE 插件、自动改代码、项目级理解
- 普通聊天几乎很难用上
而且这些 prompt 不是单独工作,而是:
用户输入 → agent 循环 → 调工具 → 再喂回模型 → 再决策
一个好的 prompt 不是一句话,它包含:上下文控制、token 预算、错误处理策略。
我们拿到 prompt,就像拿到鱼香肉丝的配方,但没有厨房,也没有食材。
2)对开发者(这才是真正受益者)
开发者可以从这次泄漏中获得至少 4 层价值:
1)直接看到 Anthropic 怎么写 system prompt
- 怎么限制模型行为(比如不乱改代码)
- 怎么设计 tool schema
- 相当于站在巨人肩上,少走弯路,减少试错时间
2)理解 Agent 范式
- 很多人做 AI Agent 会卡在“怎么让模型像人一样一步步做事”
- 泄漏的设计会展示:任务拆解方式、何时调用工具、何时停止循环
3)学习 prompt 工程的工业级写法
- 超长、结构化 prompt
- 明确规则 + 大量边界条件
- 和网上那种“prompt 技巧”完全不是一个级别
4)工程最佳实践的借鉴
工具调用、错误恢复、多轮推理
六、总结
最牛的核心、最真的护城河,在于 Claude 模型本身的能力。
我们用同一套 prompt:
- 用 Claude → 很满意的结果
- 用其他普通开源模型 → 可能完全不行
外行看热闹,内行学思路。
经验的泄漏,不是能力的泄漏。
七、题外话:400 报错背后的“个性化之痛”
在写这篇文章时,Claude 又推出了 Claude Code v2.1.92,带来一个听起来很酷的新功能——Ultraplan。
但更有意思的是:
有开发者尝试通过修改 system prompt 来获得更个性化的体验。
结果,Anthropic 的后台直接 400 报错了。
有人认为,这是针对此前“Claude Code 源码泄漏事件”的补丁。
于是问题来了:
用户花了昂贵的订阅费,却无法自由定义 AI 的行为——开发者社区出现极大质疑。
为什么 400 报错其实有必要?
在 Anthropic 的设计里,system prompt 不是普通提示词,而是:
调度中枢 + 行为约束 + 工作流程说明
它通常同时负责:
- 定义角色(你是一个 coding agent)
- 规定行为(什么时候改代码、什么时候不改)
- 工具调用规则(什么时候用哪些 tool)
- 安全限制(不能做什么)
当我们“加一点个性化”,比如:
- “说话更幽默一点”
- “多解释一点”
- “像朋友一样聊天”
可能无意中做了这些破坏:
1)打断决策逻辑
agent 本来是:分析 → 决策 → 调 tool → 返回结果
一改,可能变成:分析 → 解释 → 再解释 → 忘了调 tool
2)模糊优先级
system prompt 里通常有隐藏优先级(必须优先完成任务)
你加一句“优先让用户感觉轻松愉快”
模型会困惑:到底是完成任务,还是聊天?
3)破坏格式约束
很多 agent 依赖严格格式(JSON 输出、tool 调用结构)
你一改语气,可能直接输出自然语言 → 程序解析失败
为什么付费用户会更不爽?
预期是:“我花钱了,应该能自定义它”
但现实是:你在改的是系统内核,不是皮肤。
这就像我们想给手机换主题、换皮肤,结果去改了 iOS 内核,然后系统自然就崩了。
这反映了一个更深的问题
所有像 Claude 这样的系统都有一个矛盾:
灵活性 vs 稳定性
越开放 prompt → 越灵活 → 越容易失控
Anthropic 其实是偏 “稳” 的一派。
正确的个性化方式(而不是硬改 system prompt)
如果你真的想改,不要动 system prompt,而是:
方法1:放在 user prompt
“请用更轻松一点的语气解释下面代码:xxx”
这样不会破坏系统逻辑。
方法2:用“软约束”而不是“硬改写”
 “你必须像朋友一样聊天”
“你必须像朋友一样聊天” “在不影响任务执行的前提下,可以适当更自然一点”
“在不影响任务执行的前提下,可以适当更自然一点”
方法3:分层控制
把 prompt 拆成:
- system(不动)
- developer(轻微控制)
- user(个性化)
我对这件事的看法
- 用户没错,但认知有偏差
- 产品也有问题,但不是简单“做得烂”
更本质的是:AI 产品还没把“可控个性化”这件事做成熟。
一句话总结本文核心结论:
Claude Code 的源码泄漏是工程事故,但不是模型泄漏;
对开发者有学习价值,对普通用户影响有限;
真正值得警惕的不是“复制 Claude”,而是行业对 AI 可控性的认知仍不成熟。
如果你觉得这篇文章有用,欢迎转发给同样在关注“Claude 泄漏”的朋友。
理性吃瓜,比情绪站队更有价值。
作者:悠酱
扫一扫 微信咨询

商务合作 联系我们
 微信扫一扫
微信扫一扫




