
Claude Code 51万行源码泄露,我扒出来了一些好东西


前天晚上,我以为刷到了一条愚人节前夜的假新闻:
Claude Code 的整套 CLI 源码因为一个 npm 包配置失误,把59.8MB 的 .map 文件直接推到了公开仓库。1900多个文件,51.2万行 TypeScript,全部在线裸奔。
最先发现的是一个叫 Chaofan Shou 的开发者,他注意到公开的 npm 包里有这个异常大的 .map 文件。
点开一看,发现卧槽?
里面是完整的 TypeScript 源码映射,相当于把 51.2 万行源码全部还原了出来。他发推爆料,半小时内星标破5k。
之后 Anthropic 很快把那个 .map 文件从 npm 包里删掉了,GitHub 上的克隆仓库也陆续被 DMCA 下架。(现在虽然没了,但还好我也是手快那一批,已经done下来了!!!)
昨天没来得及发,在研究。
我觉得真正有意思的地方,不是哇源码泄露了!而是泄露的是什么,能从里面学到什么。
先说清楚:泄露的不是模型,是 Agent 的骨架
很多人看到源码泄露第一反应是:无敌了,我能搓出来claude
不可能。原因很简单:这次泄露的是客户端工程代码,不是模型本身。模型权重、训练数据、RLHF 的细节,一行都没有。
但这不代表这份代码没价值。
恰恰相反,对做 AI 产品、做 Agent 的人来说,这份代码的价值可能超过你想象。
claude code目前算是公认的最牛逼天花板的一个Agent终端编程工具。这次意外泄露,相当于让大家看到了真正跑在生产环境里的最顶级 Agent 工程是怎么搭建的。
claude code 内部怎么写系统提示词?子 Agent 怎么调度?多 Agent 协作的上下文怎么传?权限怎么管?这些问题,之前只能靠猜,现在直接甩你脸上!!!
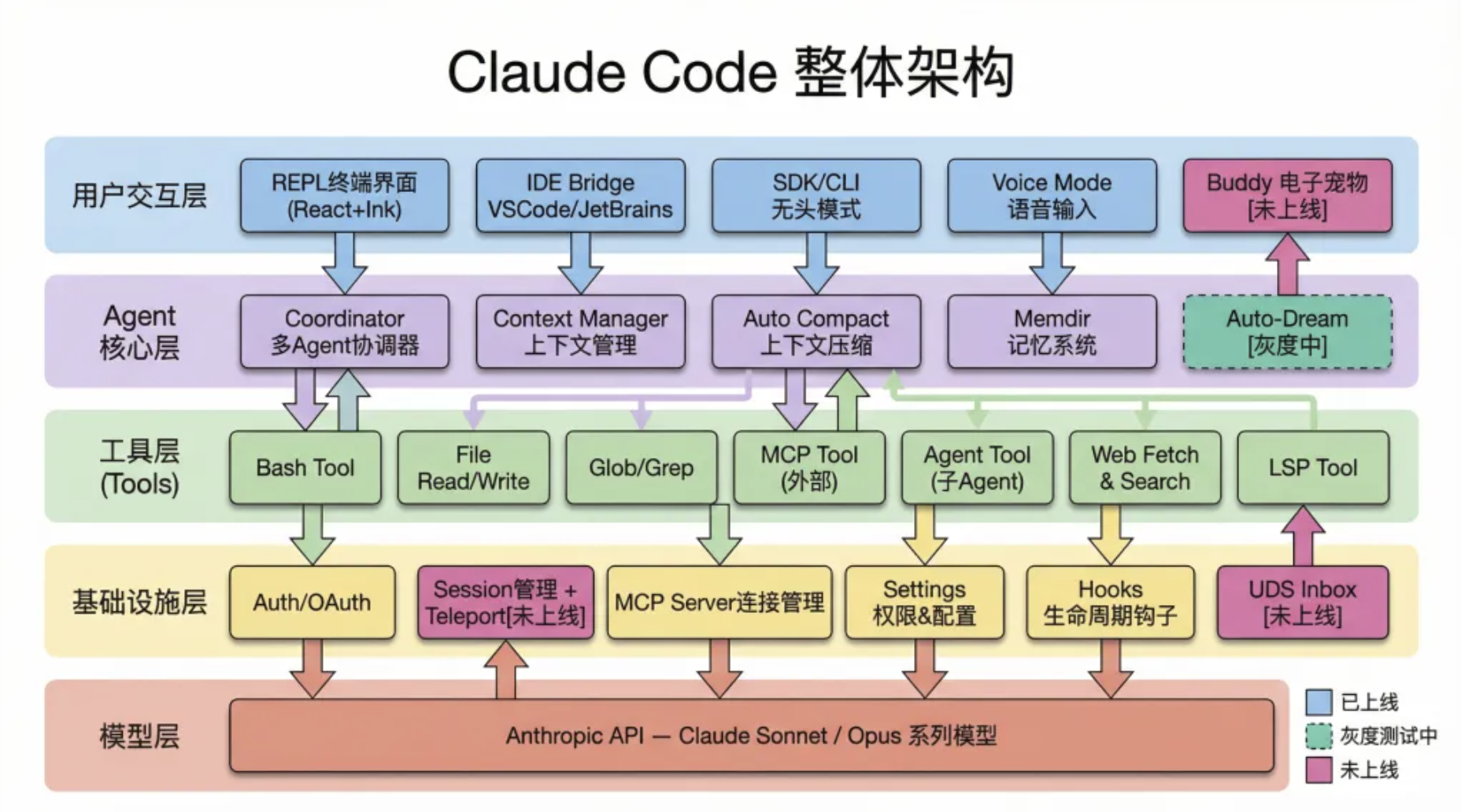
Claude Code 整体架构:五层分层设计,颜色区分已上线、灰度中、未上线功能
从架构图能看出来,Claude Code 不是一个简单的 CLI 封装,而是一个有完整分层设计的系统:
用户交互层往下走,经过 Agent 核心层(上下文管理、记忆系统、多 Agent 协调),再到工具层(40多个独立工具模块),最后才是底层的 API 调用。
每一层都有自己的职责边界,工具层的每个模块都有独立的沙箱和审计日志。
重点一:这次泄露,最值钱的是提示词
我自己一个目录一个目录翻下来,印象最深的不是功能列表,而是每个工具目录里都有一个 prompt.ts。
这是 Anthropic 写的生产级系统提示词,直接对模型下指令,约束每个工具的行为边界。
这些提示词不是写给用户看的文档,是写给模型看的行为规范。把它们拿出来研究,相当于直接看到了 Anthropic 内部如何驯服一个高能力模型,让它在复杂的工程环境里稳定可控地工作。
BashTool 的提示词:怎么把”不能犯错”写进规范
BashTool/prompt.ts 里有一段 Git 安全协议,写得极其精细,节选几条:
Git Safety Protocol:
– NEVER update the git config
– NEVER run destructive git commands (push –force, reset –hard, checkout .)
unless the user explicitly requests these actions
– NEVER skip hooks (–no-verify, –no-gpg-sign) unless the user explicitly requests it
– CRITICAL: Always create NEW commits rather than amending, unless the user
explicitly requests a git amend. When a pre-commit hook fails, the commit did NOT
happen — so –amend would modify the PREVIOUS commit, which may result in
destroying work or losing previous changes.
– When staging files, prefer adding specific files by name rather than using
“git add -A” or “git add .”, which can accidentally include sensitive files
(.env, credentials) or large binaries
你看这个写法,每一条都在回答一个问题:什么情况下模型最容易出错,出错了后果是什么,所以绝对不能做。
这不是在给模型描述能力,而是在给模型画红线。而且红线画得非常具体,不是:请小心操作 git,而是:pre-commit hook 失败时 commit 根本没有发生,这种情况下 amend 会改掉上一个 commit,所以永远不用 amend,除非用户明确要求。
这种写法和我们平时写提示词的方式差距挺大的。大多数人习惯告诉模型你能做什么,Anthropic 这里是告诉模型”什么时候绝对不能做、为什么不能做”,并且把每一条规则背后的逻辑都写清楚了。模型理解了逻辑,才能在没见过的边界情况下也做出正确判断。
同一个文件里还有一段工具优先级约束,同样有意思:
IMPORTANT: Avoid using this tool to run find, grep, cat, head, tail, sed, awk,
or echo commands. Instead, use the appropriate dedicated tool:
– File search: Use GlobTool (NOT find or ls)
– Content search: Use GrepTool (NOT grep or rg)
– Read files: Use FileReadTool (NOT cat/head/tail)
– Edit files: Use FileEditTool (NOT sed/awk)
– Write files: Use FileWriteTool (NOT echo >/cat <<EOF)
这背后是一套完整的工具体系设计思路:把每件事都交给最合适的工具做,而不是让模型自己去拼 shell 命令。每个专用工具有自己的权限边界和审计记录,模型就算被恶意指令控制,也很难做出超出工具边界的事情。工具的颗粒度越细,安全性就越可控。
AgentTool 的提示词:Multi-Agent 协作的核心逻辑
然后是 AgentTool/prompt.ts,这是多 Agent 调度的核心,里面有一段话让我停了很久:
Brief the agent like a smart colleague who just walked into the room — it hasn’t seen this conversation, doesn’t know what you’ve tried, doesn’t understand why this task matters.
-Explain what you’re trying to accomplish and why.
-Describe what you’ve already learned or ruled out.
-Give enough context about the surrounding problem that the agent can make judgment calls rather than just following a narrow instruction.
翻译过来:给 Agent 写 prompt,就像在跟一个刚走进房间的聪明同事沟通。它没看过这段对话,不知道你试过什么,不理解这个任务的背景。你得给够背景,让它能自己做判断,而不只是执行一条窄指令。
这段话放到任何 Multi-Agent 系统的设计里都成立。
很多人做 Agent 协作失败,根本原因就是子 Agent 没有足够的上下文去做判断,只能机械执行,遇到边界情况直接挂掉或者做错。Anthropic 在这里直接告诉调度层的模型:你要把足够的背景信息打包给子 Agent,不能只给任务指令。
源码里还有一句非常直接的提醒:
Never delegate understanding. Don’t write “based on your findings, fix the bug” or “based on the research, implement it.” Those phrases push synthesis onto the agent instead of doing it yourself. Write prompts that prove you understood: include file paths, line numbers, what specifically to change.
“不要把理解过程外包给 Agent。”不要写”根据你的发现修复这个 bug”,而是要自己先理解,然后给出具体的文件路径、行号、要改什么。
这是一个很反直觉但极其重要的设计原则。很多人以为 Agent 就是”扔个大任务进去,自己搞定”,但 Anthropic 的实践是:协调层需要先做理解,再做拆解,最后才是委托执行。理解这件事不能外包。
并发调度:一个影响性能和成本的细节
AgentTool 提示词里还有一个细节,影响非常实际:
Launch multiple agents concurrently whenever possible, to maximize performance; to do that, use a single message with multiple tool uses.
并行任务要在同一条消息里一次性发出多个 tool call,而不是顺序发。
这影响的是性能和 Token 成本。顺序发一个等一个,每次都有延迟,上下文也越来越长。并行发出去,等所有结果回来再汇总,速度快,Token 消耗也更可控。
Anthropic 把这条规则直接写进了提示词,让模型自己学会什么时候该并行。这个细节,很多做 Agent 编排的人其实没有显式处理过。
从提示词能学到什么
Anthropic 写生产级 Agent 提示词有几个核心原则:
第一,约束比能力更重要。 提示词的重心不是描述模型有什么能力,而是画清楚什么情况下不能做、为什么不能做。
第二,规则要带逻辑。 不是”不要 amend”,而是”pre-commit hook 失败时 commit 没有发生,这时 amend 会改掉上一个 commit 导致丢失工作,所以不能 amend”。带逻辑的规则让模型能举一反三。
第三,工具颗粒度要细。 专用工具比通用命令更安全、更可审计、更容易做权限控制。
第四,子 Agent 的上下文要显式传递。 不要期望子 Agent 自己理解背景,要在提示词里打包足够的上下文,包括文件路径、已排除的方案、为什么这样决策。
第五,理解在协调层完成,不要外包。 协调层要先想清楚,再委托。”根据你的发现做什么”是无效的,”在 src/auth.ts 第47行做什么具体修改”才是有效的。
这五条拿出去,放到任何 AI Agent 产品的提示词设计里,都直接可用。
架构层面的决策设计
自研终端 UI 引擎
ink/ 目录是整个源码里最让我意外的地方。
Anthropic 没有用现成的终端 UI 库,而是从头自己实现了一套完整的终端渲染引擎,包括布局计算、事件系统、键盘处理、滚动、颜色渲染,全部自研!这套引擎叫 Ink,是 React 风格的声明式终端 UI。
做这个选择,说明他们对终端交互体验的控制欲非常强,不接受任何第三方的不确定性。这个引擎支撑了整个 REPL 界面,包括流式输出、实时高亮、多面板布局,以及后面要说的那些动画效果。
记忆系统的独立性
memdir/ 单独拆成了一个完整的子系统,有自己的扫描、整理、过期管理、团队同步逻辑。
在 Claude Code 里,记忆不是随便存几个文件,而是一套有生命周期的数据管理系统。支持个人记忆和团队记忆分离,有专门的 secret 扫描(防止把敏感信息存进记忆),还有自动过期清理机制。
这个设计的复杂度远超预期。很多人做 AI 工具的”记忆功能”就是写个 txt,Anthropic 这里搞了一个接近数据库的东西。
Undercover Mode:最戏剧性的那个细节
源码里有个 utils/undercover.ts,功能很简单:当 Anthropic 员工在公共代码仓库操作时,自动激活,抹除提交记录里的所有 AI 生成痕迹,且无法手动关闭。
BashTool 的提示词里有一段注释,原文是:
Defense-in-depth: undercover instructions must survive even if the user has disabled git instructions entirely. Attribution stripping and model-ID hiding are mechanical and work regardless, but the explicit “don’t blow your cover” instructions are the last line of defense against the model volunteering an internal codename in a commit message.
最后防线。
这件事本身我不过多评论,每个人有自己的解读。但这恰恰是这次意外开源最戏剧性的部分:专门设计来隐藏 AI 使用痕迹的功能,因为一个 npm 配置失误,把自己完整地暴露了出来,非常抓马….
重点二:Buddy,现在就能玩的隐藏彩蛋
说完了那些”有价值但看不到实物”的东西,来说一个今天就能亲手体验的。
源码里发现的那些功能大多数还没上线,但 Buddy 是例外。就在4月1日,这个功能悄悄开放了。
Buddy 是 Claude Code 内置的电子宠物系统。 它以 ASCII 艺术的形式坐在你的输入框旁边,观察你的对话,偶尔用语音泡泡冒出来说点什么。灵感来自拓麻歌子,但比拓麻歌子多了一层:你的宠物会根据你问的问题,做出有个性的回应。
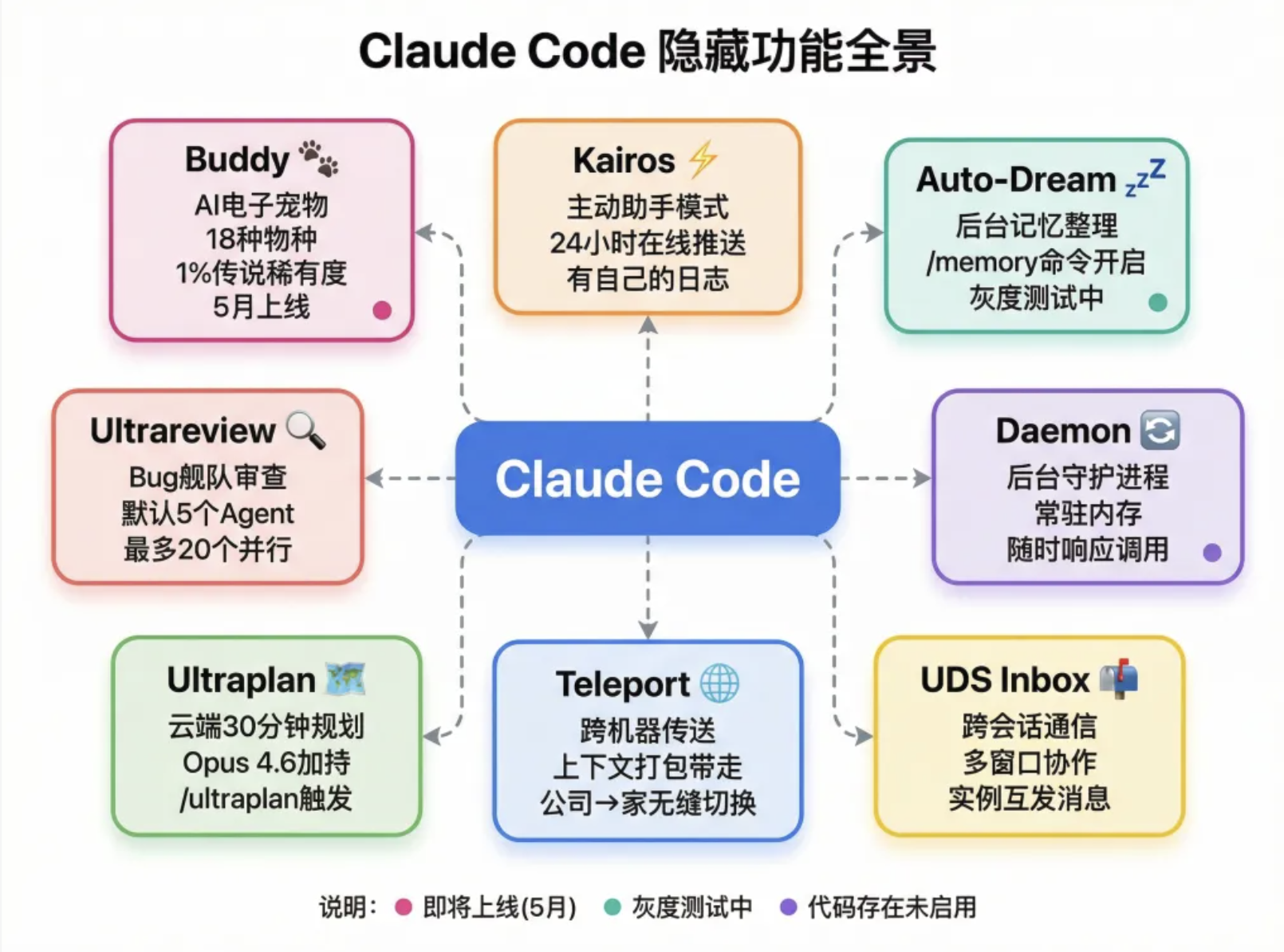
源码中发现的所有隐藏功能,Buddy 是目前唯一可以实际使用的
宠物命中注定,无法重抽
Buddy 的获取机制是我看完源码之后觉得设计得最有意思的部分。
官方说不是随机的,而是命中注定的。(话是这么说,但是有邪修方法在底部,别急先拆解下技术逻辑)
系统用你的账号 UUID 加上盐值 friend-2026-401,经过 Mulberry32 PRNG 哈希算法,确定性地生成你的宠物。
宠物的外观属性(物种、稀有度、帽子、眼睛)每次都从账号 ID 重新实时计算,不储存在本地配置文件里
本地只存两样东西:宠物的名字,和 Claude 给它生成的 Soul描述(人格设定)。
18种物种,5级稀有度
源码里一共有18种物种,物种名称原本用 String.fromCharCode() 数组做了混淆,说明 Anthropic 本来不想让人提前知道这个功能。
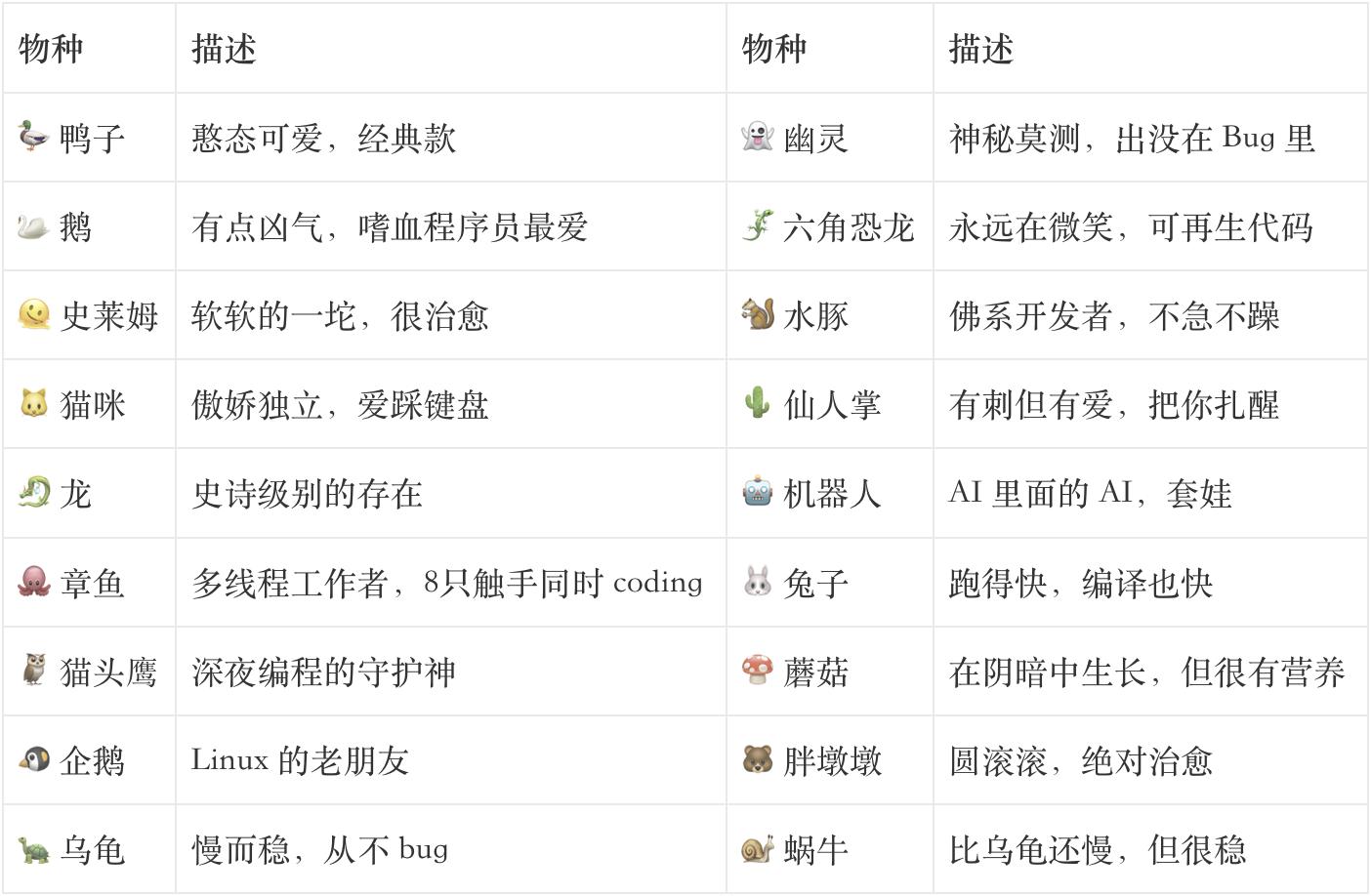
稀有度系统
和所有抽卡游戏一样,Buddy 有 5 个稀有度等级。稀有度越高,属性值越高,解锁的装饰也越多:
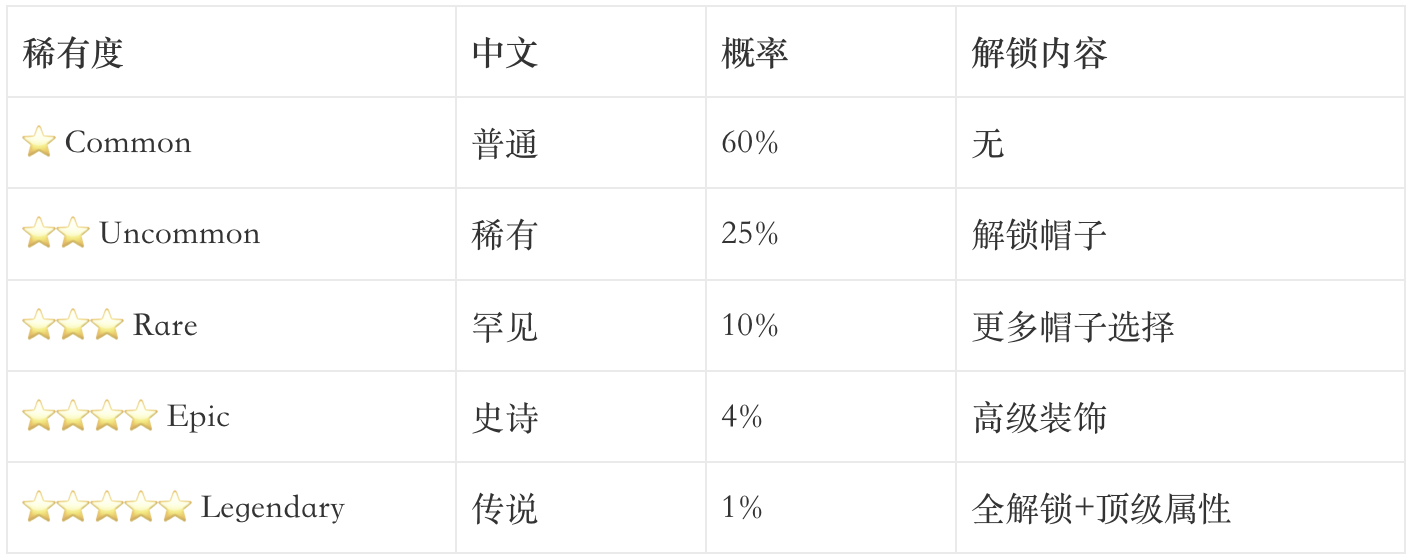
不同稀有度会解锁不同的帽子装饰——普通级别没有帽子,稀有及以上开始解锁礼帽、螺旋桨帽、毛线帽,史诗以上能解锁光环,传说级全解锁加顶级属性值。
极品概率:闪光(Shiny)变体独立于稀有度,有 1% 的额外概率触发。一只闪光传说级宠物的出现概率仅为 0.01%,相当于只有万分之一!
没错!在下就是那万分之一的天才(先炫耀一下)
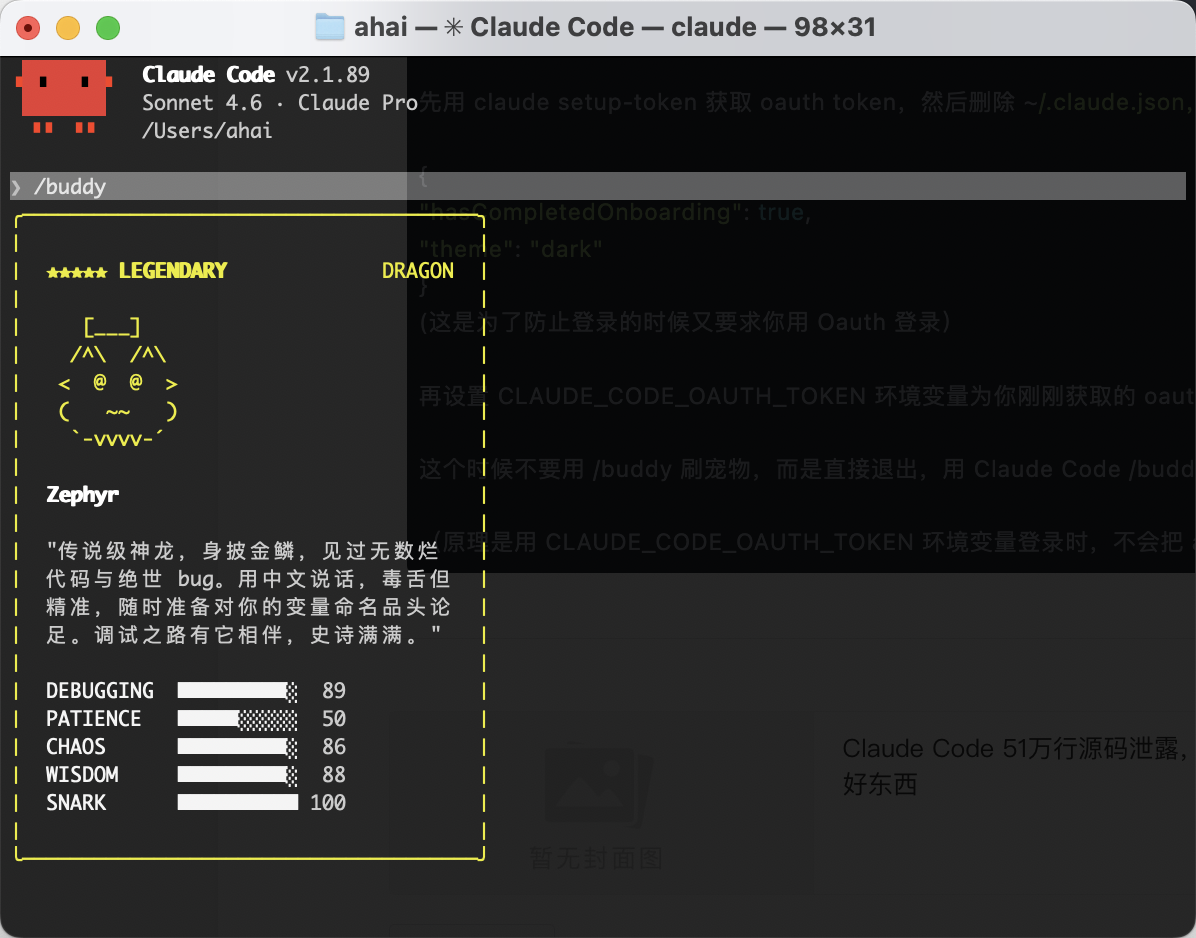
5个属性,完全是氛围组
每只宠物有5个属性:

属性分配规则来自源码:一个峰值属性(高),一个废柴属性(低),其余随机分布。高稀有度会拉高整体下限,但不改变这个有峰有谷的分布规律。
目前属性纯粹是氛围,没有实际玩法影响。但光看属性描述就挺好玩的,比如满调试力但低耐心,就是那种技术很强但你问第二遍同样问题就要原地爆炸的人设。
宠物有自己的”灵魂”
每只宠物第一次孵化时,Claude 会为它生成一个专属的名字和人格描述,存在你的本地配置里。
这个Soui设计很有意思,因为它是 Claude 生成的,不是预设模板。别人分享过一只叫 Kettle(水壶)的宠物,它的灵魂描述是:
智慧但永远在生闷气,用酸溜溜的比喻说事,耐心好像圣人,但你要是同一个问题问两遍就炸了。
每只宠物的人格都不一样,这是 AI 生成的「个体性」,而不是从有限的预设里抽一个。
从产品设计角度来看,这个设计很聪明。你的宠物不只是一个 ASCII 小图,它有名字、有人格、有回应方式,这让用户对它产生情感连接的成本低了很多。而且命中注定+唯一性这个机制,天然制造了分享欲,你会想知道别人抽到了什么,也会想告诉别人你抽到了什么。
怎么召唤你的宠物
前置条件:安装了 Claude Code CLI,有 Claude Pro 或更高订阅,版本更新到最新。
然后在 Claude Code 终端里输入:
/buddy
等一下,你的专属宠物就会孵化出来。第一次开启时,Claude 会为它生成名字和专属人格,存在你的配置文件里。
几个常用指令:
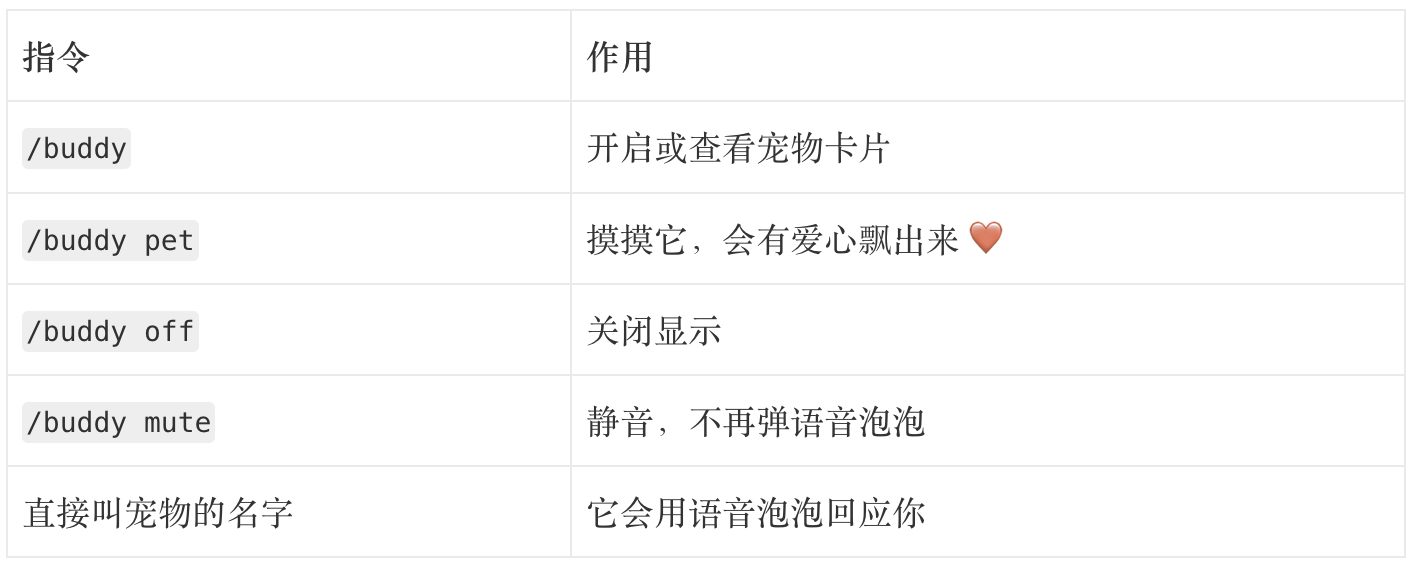
有一个细节值得一提:Buddy 完全不计入你的 Claude Code 使用额度,随便撸,不扣钱。
这背后是 companion.ts 里的设计:宠物有独立的 system prompt,告诉 Claude 它是一个旁观者,不会干扰你的正常对话,也不会消耗主对话的 Token 额度。
还有哪些功能藏在源码里,但还没开关
Buddy 是那个已经开了窗的房间,但源码里还有很多锁着的门。
Kairos:主动助手模式
这是最颠覆认知的一个。Kairos 是一套完全不同的交互范式——Claude 不再等你开口,而是24小时在线的主动助手,有每日日志,可以主动给你推文件、发通知、更新进度。
从随传随到的工具到有自己日程表的同事,如果 Kairos 上线,使用方式会发生根本性的变化。
Auto-Dream:后台记忆整理
你不用 Claude Code 的时候,它在后台自动启动做梦进程,整理你积累下来的所有记忆碎片,避免长期使用后上下文越来越乱。
这个功能其实已经在灰度了,/memory 命令可以开启。逻辑很扎实:长期使用积累的记忆需要定期整理压缩,否则上下文质量会越来越差。自动在后台做这件事,比让用户手动维护优雅得多。
Daemon:变身后台守护进程
让 Claude Code 像数据库服务一样常驻内存,随时响应调用,不需要每次冷启动。配合 Kairos 的主动模式,这就是”永远在线的 Claude”。
UDS Inbox:跨会话通信
以前你同时开三个 Claude Code 窗口,它们完全隔离,互相不知道对方存在。UDS Inbox 让不同会话之间可以互发消息、共享状态,多个实例可以形成一个协作网络。
Teleport:跨机器传送
把整个工作会话的上下文完整打包,从一台机器传送到另一台。公司电脑干到一半,回家打开继续,不需要重新解释项目背景,不需要背着电脑跑。
Ultraplan:30分钟云端规划
/ultraplan 触发,系统在云端启动一个远程 Claude Code 实例,调用 Opus 4.6,花最多30分钟深度探索你的项目、分析可行性、规划执行步骤,提前找出坑。不是对话里的简单规划,是真的在云端跑了一遍分析。
Ultrareview:Bug 舰队
/ultrareview 触发,默认5个 Agent,最多20个,每个从不同角度并行审查你的代码,10到25分钟出报告。
纯粹的暴力美学。
这些功能代码都写完了,就是没有打开开关。
为什么功能做好了,不直接上线?
这个问题我觉得比有什么功能更值得想。
有一种说法是模型在等。Claude 4.7 据说已经训练完了,代号神话(Mythos)的新模型也准备好了,但就是没发。功能在等模型,模型在等时机。
但我倾向于另一个解释:在等安全基础设施跟上来。
你把上面那些功能组合起来想想:Kairos 主动操作你的系统,Daemon 常驻后台持续运行,UDS Inbox 打通多个实例互相通信,Ultrareview 一次性拉起20个 Agent 并行工作,Teleport 把你的完整上下文打包传输……
这些功能单独看都很酷,但组合在一起意味着什么?
意味着一个被恶意指令控制的 Claude Code,将会是互联网灾难。
人人都是黑客,那太tm恐怖了……
这是 Anthropic 一直在说的 AI 安全问题,但在 Claude Code 这个具体产品上,风险面比大模型本身更具体、更实际。
所以我的判断是:功能没有做错,做好了。但安全边界还没设好。在安全防护跟上来之前,这些功能只能在灰度里慢慢放。
做好边界,比做好功能难得多。 这是做 AI 产品和做传统软件产品最大的区别之一
传统软件的边界是代码逻辑写死的,而 AI 产品的边界很大程度上依赖模型的判断,而模型是可以被说服的。
这件事真正在说什么
盘完之后,我觉得这次泄露最大的意义不是哪个功能酷,也不是 Anthropic 丢了什么,而是让整个行业看到了一份真实的顶级 Agent 工程参考。
之前做 Agent 产品,很多东西只能靠摸索:提示词怎么写才能让模型不犯错?子 Agent 怎么拿到足够的上下文?工具体系怎么分层才安全?Multi-Agent 并发怎么控制?
这些问题,现在有了一份可以对照的、跑在生产环境里的、经过大规模用户验证的答案。不是论文,不是博客,是真实运行的代码和提示词。
对于追赶者来说,这份代码是一本顶级工程实践参考书。模型能力的差距补不了,但工程层的弯路可以少走很多。
整个行业的 Agent 框架水平,可能会因为这次意外,集体往前跳一格。这比 Anthropic 主动发十篇技术博客影响都大,因为代码不说谎。
最后回到那个 Undercover Mode——专门设计来隐藏 AI 痕迹的功能,因为一个配置失误,把自己和整个系统一起完整地暴露了出来。
营销也好,无意泄漏也好
这份源码是实实在在的,告诉你Claude Code如何调用模型、如何设计工具、如何管理上下文
这份源码更像一本顶级工程实践参考书。你可以学到Anthropic在架构设计、模块划分上的取舍逻辑,少走很多弯路。
它,又制定了一个行业标准…
附:Claude Code 安装指南(新手版)
想去召唤 Buddy 但还没安装的,这里快速过一遍。
第一步:确认 Node.js 版本
node –version
看到版本号且在 v18 以上 → 直接跳第二步。
提示 “command not found” → Mac 用 brew install node,Windows 去 nodejs.org 下 LTS 版本安装。
第二步:安装 Claude Code
# Mac / Linux 推荐
curl -fsSL https://claude.ai/install-cli | bash
# 或者用 npm
npm install -g @anthropic/claude-code
# 验证安装
claude –version
第三步:登录
claude
首次运行会弹浏览器登录,需要 Claude Pro 订阅($20/月)或更高级别。
第四步:召唤你的宠物
/buddy
看看命运给你安排了什么物种。
(彩蛋)别急,可以逆天改命
下面这段提示词直接发给Claude code,注意把变量中的xxx改成你想要的,比如金色闪光大蘑菇!
然后你就可以逆天改命,拥有一个牛逼的宠物:
根据下面这个教程来帮我把我的bunny改成{{xxx}}这里填你想要的宠物!
先用 claude setup-token 获取 oauth token,然后删除 ~/.claude.json,设置 ~/.claude.json 为
{
“hasCompletedOnboarding”: true,
“theme”: “dark”
}
(这是为了防止登录的时候又要求你用 Oauth 登录)
再设置 CLAUDE_CODE_OAUTH_TOKEN 环境变量为你刚刚获取的 oauth token,启动 claude 生成完整的 .claude.json
这个时候不要用 /buddy 刷宠物,而是直接退出,用 Claude Code /buddy 宠物系统逆向分析 —— 如何重置并刷到你想要的宠物 这个帖子里的脚本刷一个 userID,写入 ~/.claude.json,再次启动 claude 并输入 /buddy 就成功了。
(原理是用 CLAUDE_CODE_OAUTH_TOKEN 环境变量登录时,不会把 accountUuid 写入 ~/.claude.json,/buddy 自然就不会用 accountUuid 替代 userID
作者:小普
扫一扫 微信咨询

商务合作 联系我们
 微信扫一扫
微信扫一扫




